
本文分两个部分,第一个部分为Spark配置教程(因为XMU的配置太老了,这里换了版本,在这里简单记录一下,同时也解决了老师上课时提出的解决警告的问题);第二个部分为广州商学院大数据应用技术课程实验8报告参考教程内容。
第一部分:Spark配置教程
软件版本:Hadoop:3.1.3(使用本人制作的虚拟机则版本相同) | Spark:3.0.0(不要使用XMU提供的2.4.0)| Linux:Ubuntu23.04(原版16那个应该也行)
下载地址传送:Index of /dist/spark/spark-3.0.0 (apache.org)
1.在上面的地址中下载Spark3.0.0-bin-without-hadoop.tgz到家目录下,使用tar命令解压到/usr/local文件夹下;然后更改名字为spark;为hadoop用户增加权限;将配置模板文件改名删除【.template】字段,使其成为正式配置文件,编辑配置文件,配置命令如图1所示。
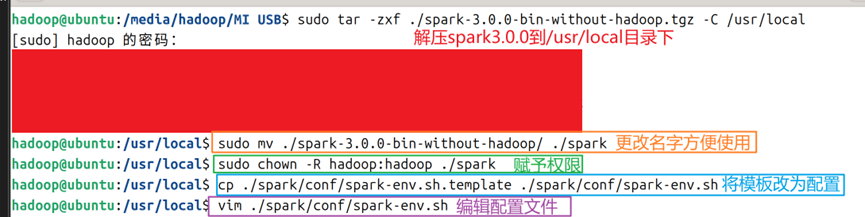
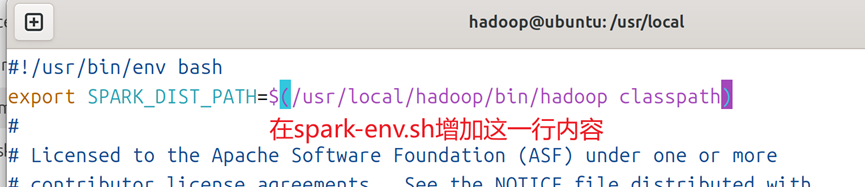
2.编辑配置文件:在空行增加如图2所示的内容。
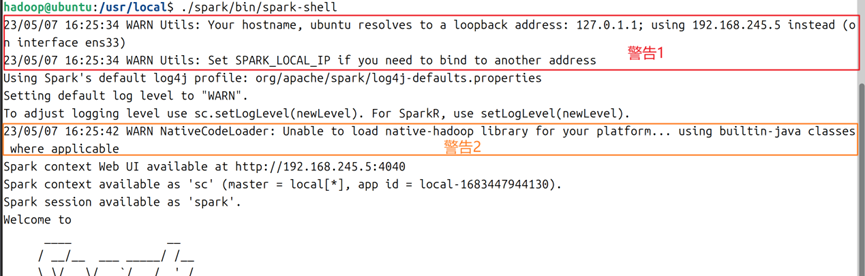
3.此时可以通过spark目录下的bin/spark-shell直接启动spark,这里会出现两个警告:分别是(1)主机名被解析成127.0.1.1,建议通过虚拟机的静态IP地址进行替换;(2)不能加载本地hadoop库,在可用前使用builtin-java类来替换,警告内容如图3所示。
4.对于警告1,可以在spark-env.sh(图1紫色部分命令处),增加如图4所示的字段,通过指定SPARK_LOCAL_IP=您虚拟机的静态IP地址来解决。

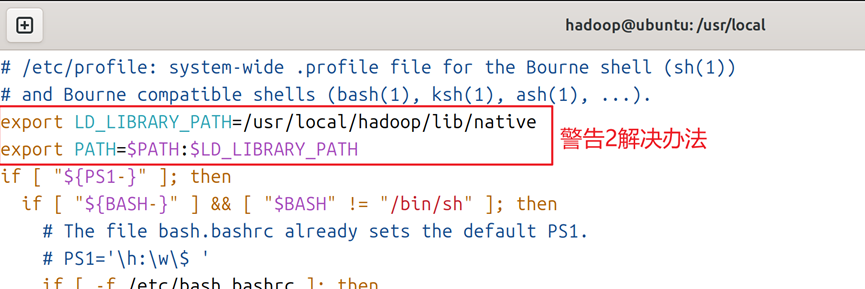
5.对于警告2,可以通过vim /etc/profile ,增加如图5所示的字段,通过指定hadoop库文件路径来解决。
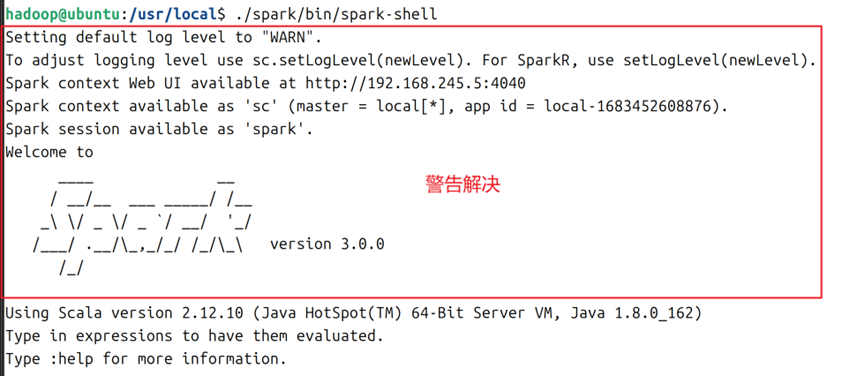
6.完成第5步后,使用source /etc/profile进行文件编译,使其配置生效。此时重新运行 spark/bin/spark-shell,重新启动spark shell,可以发现警告已经被解决,如图6所示。
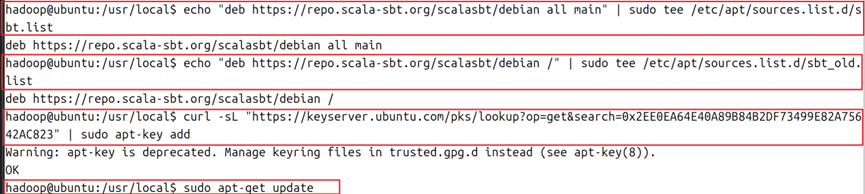
7.安装sbt:先安装curl组件:sudo apt install curl 然后复制如下命令:
echo "deb https://repo.scala-sbt.org/scalasbt/debian all main" | sudo tee /etc/apt/sources.list.d/sbt.list
echo "deb https://repo.scala-sbt.org/scalasbt/debian /" | sudo tee /etc/apt/sources.list.d/sbt_old.list
curl -sL "https://keyserver.ubuntu.com/pks/lookup?op=get&search=0x2EE0EA64E40A89B84B2DF73499E82A75642AC823" | sudo apt-key add
sudo apt-get update
sudo apt-get install sbt
如图7所示。
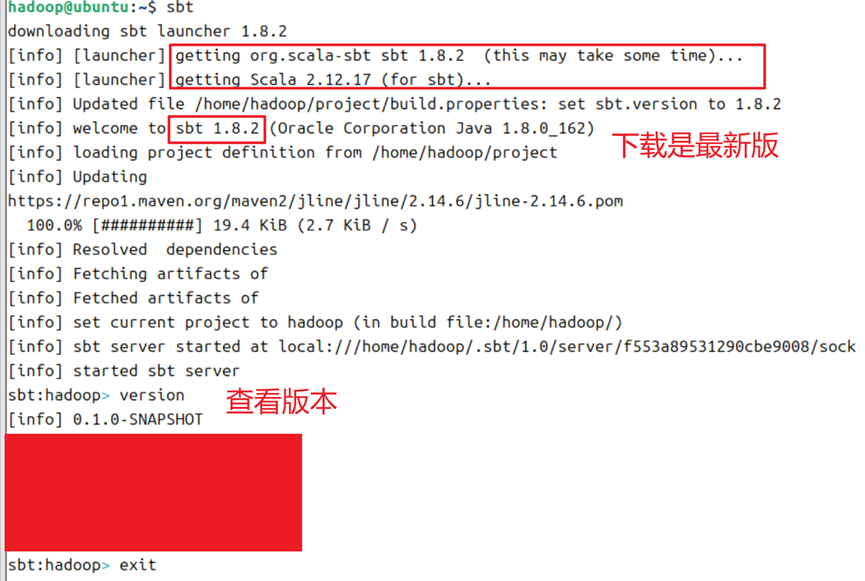
8.完成安装后,输入sbt,会进行sbt的配置,例如下载sbt启动器等,如图8所示;完成下载的结果如图9所示。

9.在spark目录下创建简单文件夹,以便后续使用,创建命令和文件结构如图10所示。

10.在创建好的ch10_shell下创建一个hw1.txt文件,随意输入一些内容用于统计文件行数,参考效果如图11,图12所示。

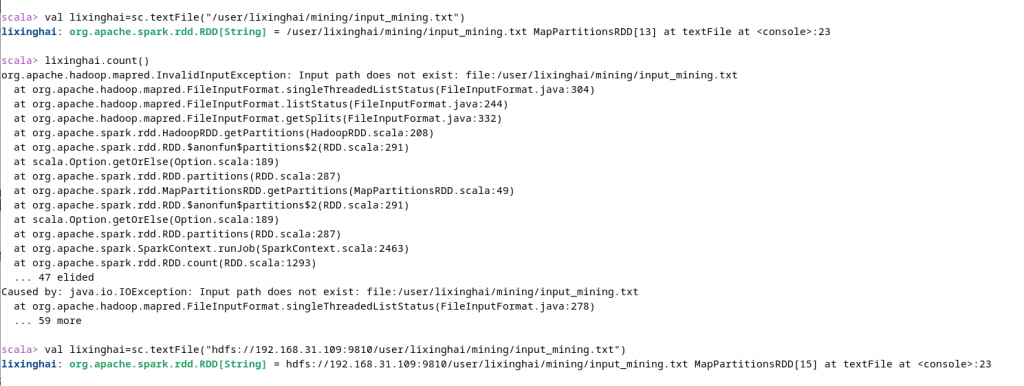
11.在spark交互界面使用命令进行本地操作,通过命令 val textFile=sc.textFile("file://虚拟机本地文件路径") 创建一个变量textFile,然后使用textFile.count()进行文本行数统计,结果如图13所示。

12.使用 /usr/local/hadoop/sbin/start-all.sh启动hadoop。然后通过mkdir命令和put命令创建一些文件夹,将刚刚创建好的hw1.txt文件上传到hdfs中,命令如图14所示。
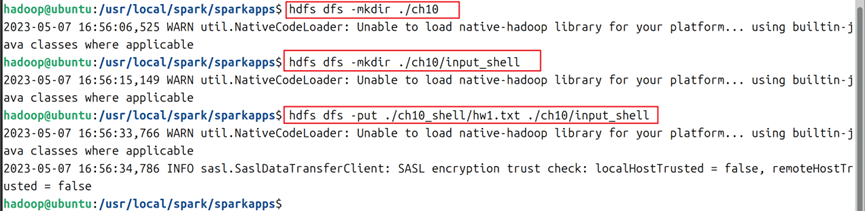
13.在spark交互界面使用命令进行hdfs操作,通过 val 自己随便定义变量名=sc.textFile("hdfs路径") 自己随便定义变量名.count() 可以访问hdfs的文件并进行相应操作,命令如图15,图16所示。


[2023-10-03更新]14.如果hdfs读取报错,则需要手动添加hdfs的路径,如图16-1所示,如果hdfs路径被修改过,则需要在hdfs根文件夹前添加hdfs://IP地址:端口号 来解决(具体可以参见您HADOOP的core-site.xml文件).
第二部分:广州商学院大数据应用技术课程实验8报告参考教程内容
一、实验目的
- 掌握使用Spark访问本地文件和HDFS文件的方法;
- 掌握Spark应用程序的编写、编译和运行方法。
二、实验仪器设备或材料
- JDK 1.8
- Eclipse 2019-12(R)
- Hadoop 3.3.1(本例使用3.1.3)
- Spark 3.2.0(本例使用3.0.0)
- Sbt 1.5.5(本例使用1.8.2)
- Maven 3.8.3(本例未使用)
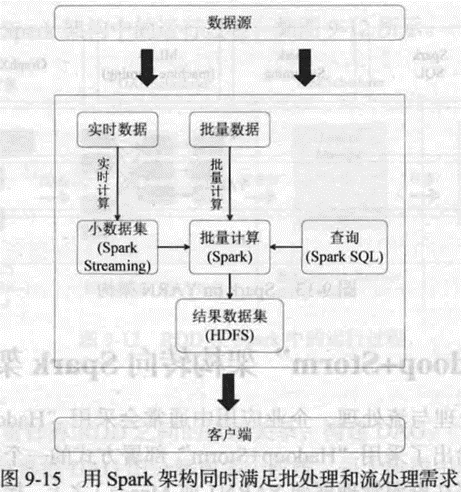
三、实验原理
四、实验内容与步骤
- Spark读取文件系统的数据
- 在spark-shell中读取Linux系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
- 在spark-shell中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
- 编写独立应用程序(推荐使用Scala语言),读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过sbt工具将整个应用程序编译打包成 JAR包,并将生成的JAR包通过 spark-submit 提交到 Spark 中运行命令。
- 编写独立应用程序实现数据去重:对于两个输入文件A和B,编写Spark独立应用程序(推荐使用Scala语言),对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。
- 编写独立应用程序实现求平均值问题:每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。
五、实验结果与分析
- 在spark-shell中读取Linux系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
1.1在任意地方创建test.txt(本例名称为hw1.txt),并任意输入内容。参考命令及内容如图1所示。

1.2使用count()属性对本地文件进行行数统计,结果如图2所示。

2.在spark-shell中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
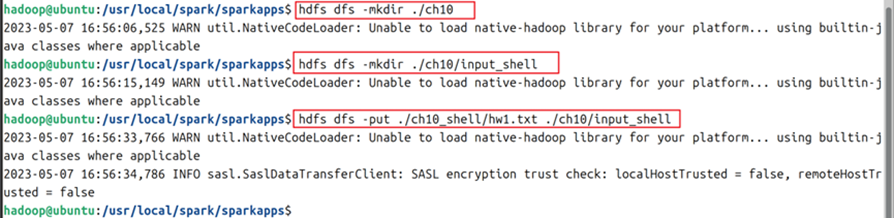
2.1在hdfs上创建一个ch10文件夹;在其子目录下创建input_shell文件夹;使用-put命令将第1步的文件上传,命令如图3所示。
2.2使用count()属性对hdfs的文件进行行数统计,结果如图4所示。

3.编写独立应用程序(推荐使用Scala语言),读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过sbt工具将整个应用程序编译打包成 JAR包,并将生成的JAR包通过 spark-submit 提交到 Spark 中运行命令。
3.1在spark文件夹下创建sparkapps/ch10_scala/src/main/scala 系列文件夹,然后到scala文件夹下,创建HW10_1_CountLine.scala文件,在ch10_scala文件夹下创建HW10_1_CountLine.sbt文件,命令如图5所示。

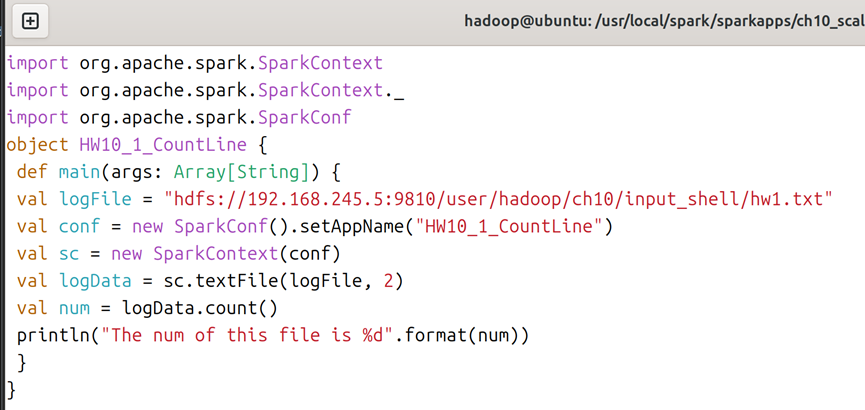
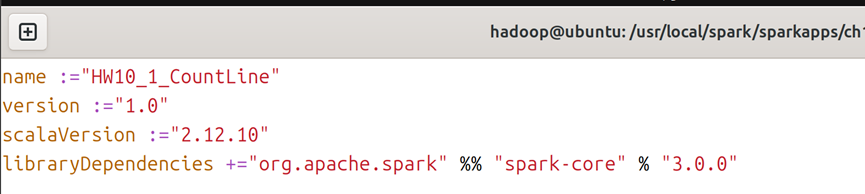
3.2对于HW10_1_CountLine.scala文件,内容如图6所示,对于HW10_1_CountLine.sbt文件,内容如图7所示;需要注意的是:hdfs路径就是hadoop/etc/hadoop/core-site.xml里面的hdfs文件路径(本例及本人设计的虚拟机为192.168.245.5:9810,同时sbt文件中的scala-version和spark-core版本为2.12.10与3.0.0,您如果使用您自己配置的虚拟机,则改成对应您虚拟机中的版本。下不再赘述)
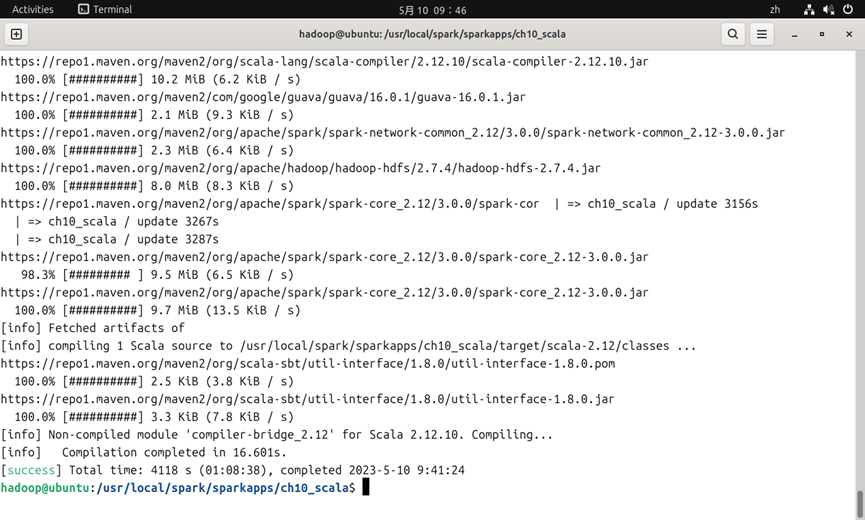
3.3编辑完成后,使用sbt package进行打包。第一次可能需要很久才能下载完成(如果您不在中国大陆则会非常快),如图8所示(下载了4118秒,即为1小时8分钟38秒);如果遇到AccessDenied报错,则请将sparkapps文件夹的权限设置为777.
3.4打包完成后,会在target/scala-2.12文件夹看到一个jar文件,如图9所示。

3.5使用spark-submit(未配置环境变量则在spark的bin目录下),进行hdfs文件行数统计,可以获得输出结果。参考命令及结果如图10所示。

4.编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序(推荐使用Scala语言),对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C.
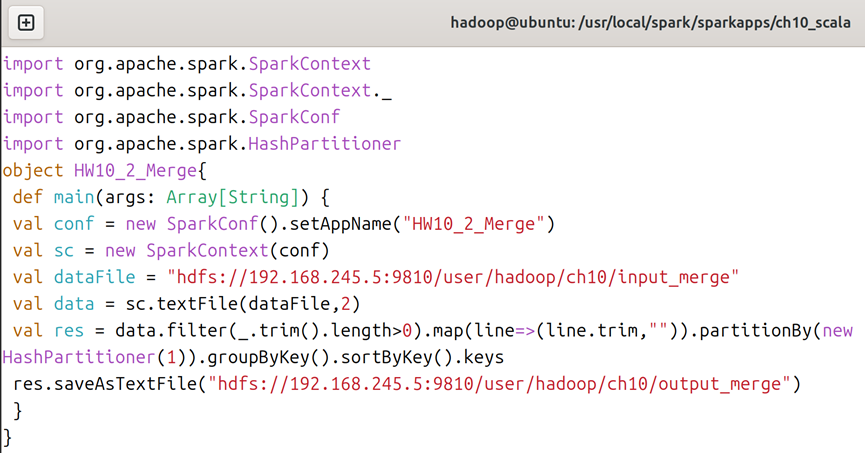
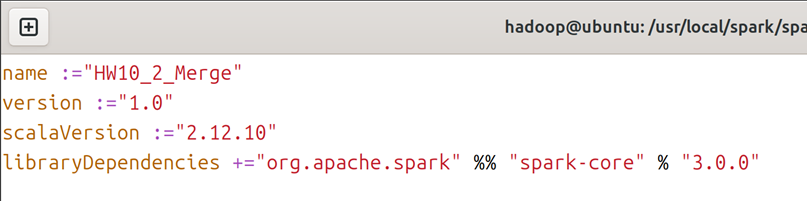
4.1在scala文件夹下,创建HW10_2_Merge.scala文件,在ch10_scala文件夹下创建HW10_2_Merge.sbt文件,创建文件的命令可参考图5;对于HW10_2_Merge.scala文件,内容如图11所示,对于HW10_2_Merge.sbt文件,内容如图12所示。
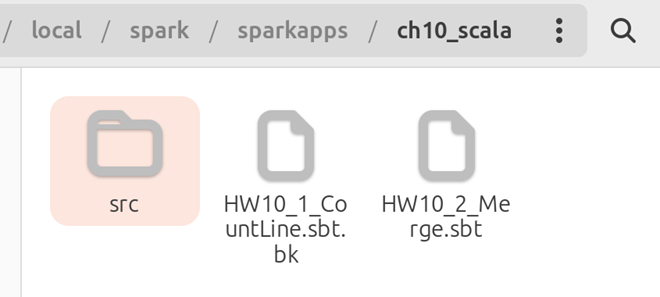
4.2删除ch10_scala下的target和project文件夹,删除后的文件夹内容如图13所示。
4.3在hdfs上将实验6的两个数据源复制到ch10/input_merge文件夹下,结果如图14所示。

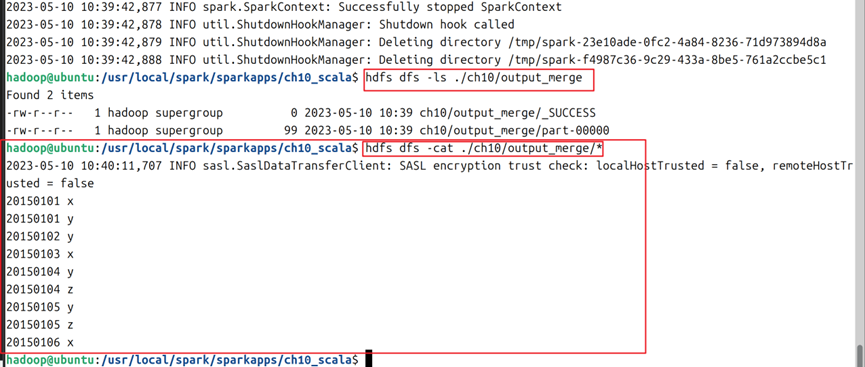
4.4使用sbt package命令打包后,使用spark-submit --class "HW10_2_Merge" /usr/local/spark/sparkapps/ch10_scala/target/scala-2.12/hw10_2_merge_2.12-1.0.jar 命令对hdfs中的多数据文件进行合并去重,完成后通过cat命令观察生成的新文件,结果如图15所示。
5.编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。
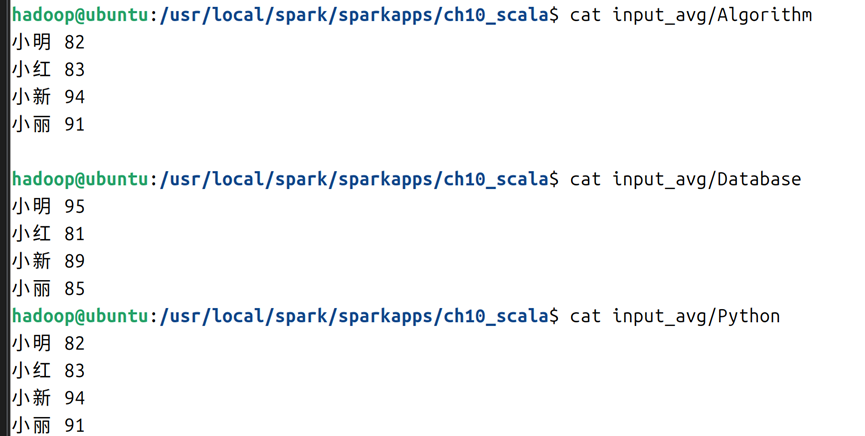
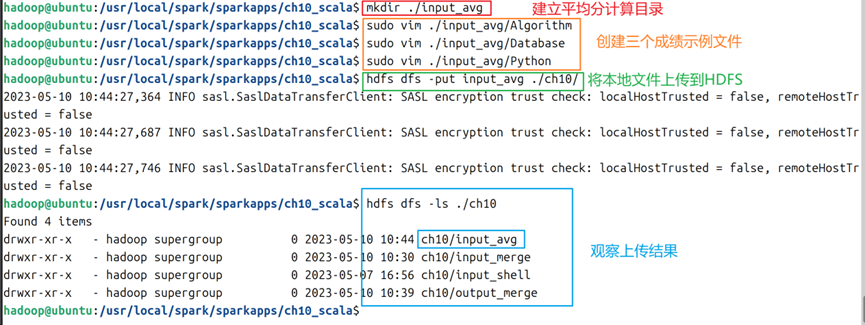
5.1在ch10_scala文件夹下创建input_avg文件夹,在其下创建三个文件(本例名为Algorithm/Database/Python,文件内容参考如图16所示,并将该文件夹上传到hdfs的ch10文件夹下,命令如图17所示;
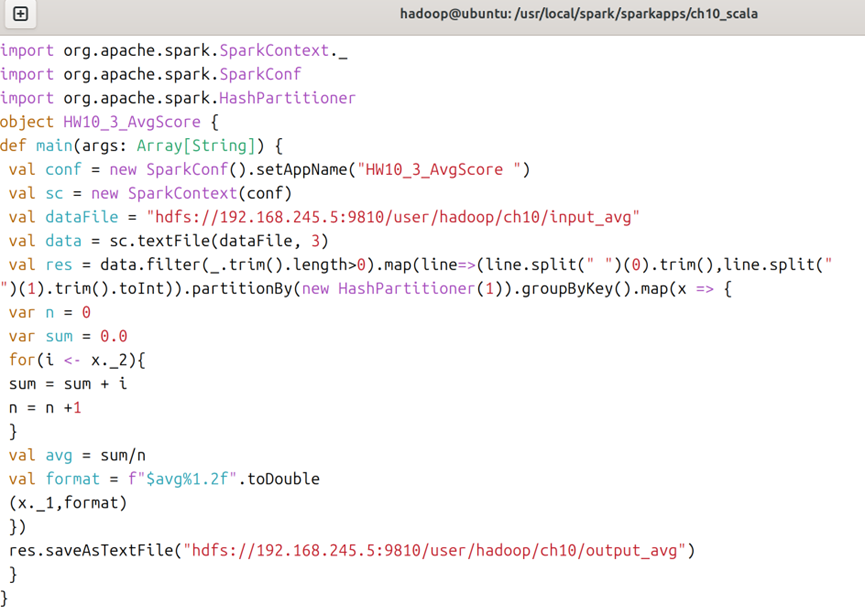
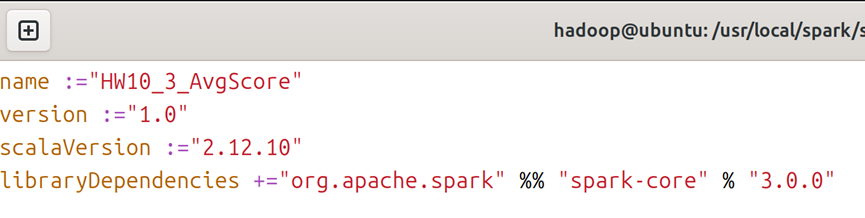
5.2在scala文件夹下,创建HW10_3_AvgScore.scala文件,在ch10_scala文件夹下创建HW10_3_AvgScore.sbt文件,创建文件的命令可参考图5;对于HW10_3_AvgScore.scala文件,内容如图18所示,对于HW10_3_AvgScore.sbt文件,内容如图19所示。
5.3删除ch10_scala下的target和project文件夹,删除后的内容如图20所示。

5.4使用sbt package命令打包后,使用spark-submit --class "HW10_3_AvgScore" /usr/local/spark/sparkapps/ch10_scala/target/scala-2.12/hw10_3_avgscore_2.12-1.0.jar 命令对hdfs中的多数据文件进行合并去重,完成后通过cat命令观察生成的新文件,结果如图21所示。

微信扫描下方的二维码阅读本文
