
一、实验目的
- 通过实验掌握基本的MapReduce编程方法;
- 掌握用MapReduce解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等。
二、实验仪器设备或材料
- Ubuntu 20.0.1
- Hadoop 3.3.1(至少完成伪分布模式)
- JDK 1.8.0_301
- Eclipse 2019-12(R)
三、实验原理
首先,在Linux系统本地创建两个文件,即文件wordfile1.txt和wordfile2.txt。在实际应用中,这两个文件可能会非常大,会被分布存储到多个节点上。但是,为了简化任务,这里的两个文件只包含几行简单的内容。需要说明的是,针对这两个小数据集样本编写的MapReduce词频统计程序,不作任何修改,就可以用来处理大规模数据集的词频统计。
文件wordfile1.txt的内容如下:
I love Spark
I love Hadoop
文件wordfile2.txt的内容如下:
Hadoop is good
Spark is fast
假设HDFS中有一个/user/hadoop/input文件夹,并且文件夹为空,请把文件wordfile1.txt和wordfile2.txt上传到HDFS中的input文件夹下。现在需要设计一个词频统计程序,统计input文件夹下所有文件中每个单词的出现次数,也就是说,程序应该输出如下形式的结果:
fast 1
good 1
Hadoop 2
I 2
is 2
love 2
Spark 2
四、实验内容与步骤
1.输入
2.处理
(1)Map的处理逻辑
(2)Reduce的处理逻辑
(3)main()测试
3.输出
(1)编译打包
(2)运行jar
五、实验结果与分析
1.创建文件wordfile1和wordfile2两个文件,命令如图1所示。

2.在两个文件中输入一些文本,这里以实验要求文本为要求,回显文件内容如图2所示。

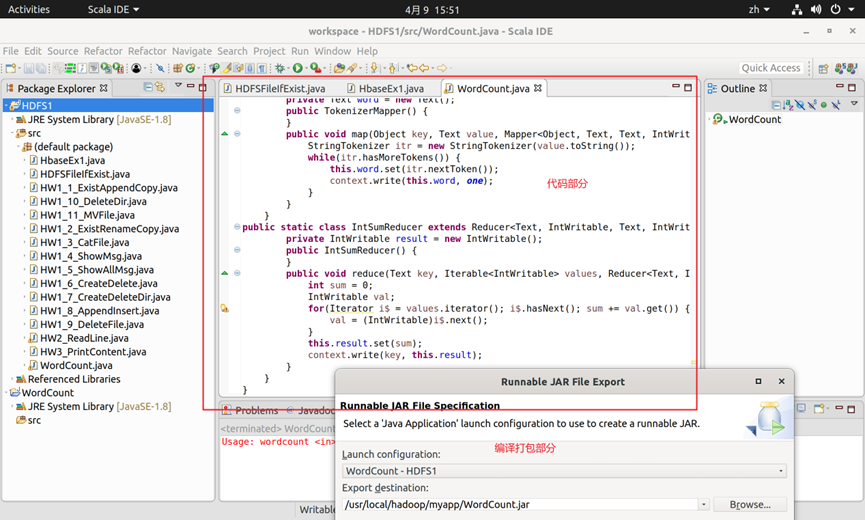
3.在Eclipse中新建一个WordCount的类,然后通过JAVA API编程进行打包(代码可至文末附件下载)。上传到Hadoop服务容器内,代码部分内容如图3所示。
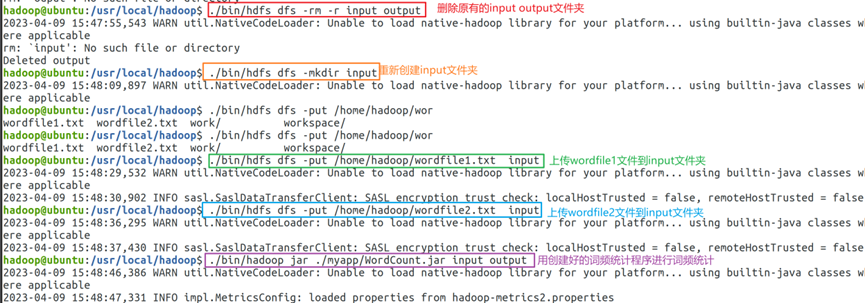
4.通过dfs命令删除Hadoop容器内的input output文件夹,重新创建input文件夹(这里也可通过删除input下所有文件完成),上传wordfile1,wordfile2到input文件夹。最后通过调用本地创建好的Jar包文件读取input文件夹中文件内容进行词频统计,结果输出到output文件夹中(如果已有同名文件夹,会输出失败),过程命令如图4所示。
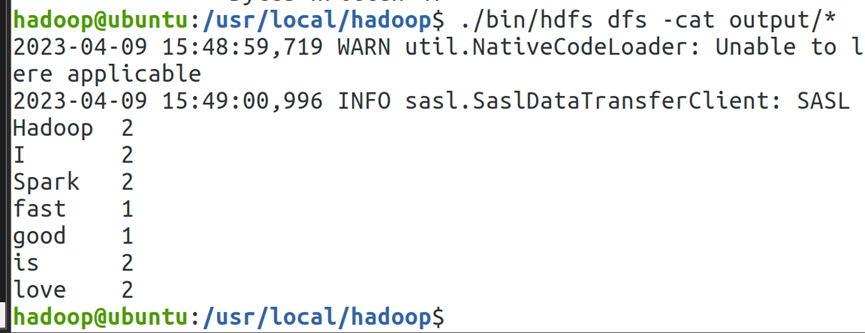
5.使用cat命令回显output文件夹下的内容,可见成功完成词频统计。如图5所示。
附件下载
微信扫描下方的二维码阅读本文
