
一、实验目的
- 通过实验掌握基本的MapReduce编程方法;
- 掌握用MapReduce解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等。
二、实验仪器设备或材料
- Ubuntu 20.0.1
- Hadoop 3.3.1(至少完成伪分布模式)
- JDK 1.8.0_301
- Eclipse 2019-12(R)
三、实验原理
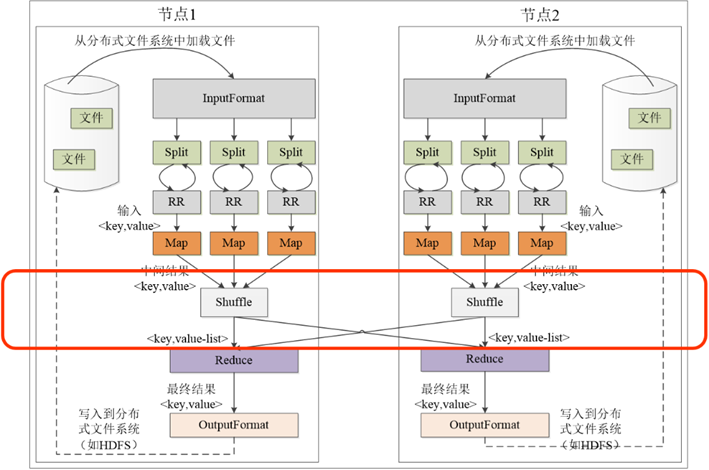
Map函数+Reduce函数+Shuffle过程
四、实验内容与步骤
1.Java API编程实现文件合并和去重操作
(1)输入
(2)处理
(3)输出
2.Java API编程实现对输入文件的排序6
(1)输入
(2)处理
(3)输出
3.Java API编程实现对给定的表格进行信息挖掘10
(1)输入
(2)处理
(3)输出
五、实验结果与分析
0.本教程第1-5步为Java API编程实现文件合并和去重操作;7-10步为Java API编程实现对输入文件的排序;12-15步为Java API编程实现对给定的表格进行信息挖掘。相关输入文件和类文件请至附件下载。
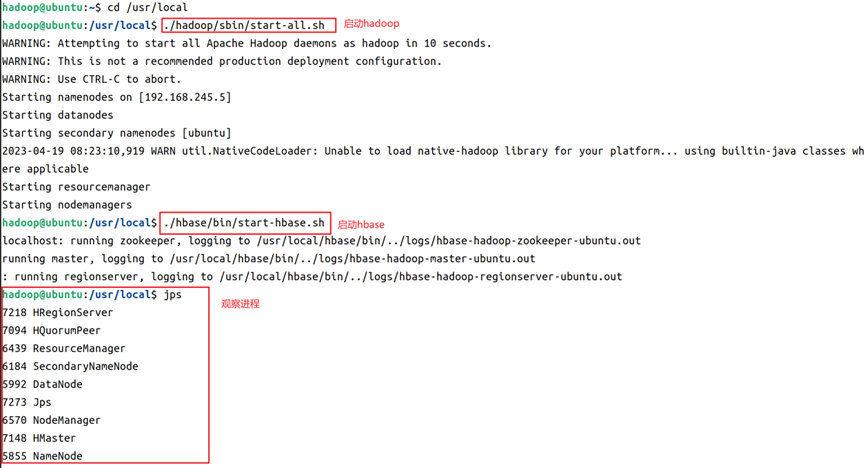
1.启动hadoop和hbase,命令和结果如图1所示。
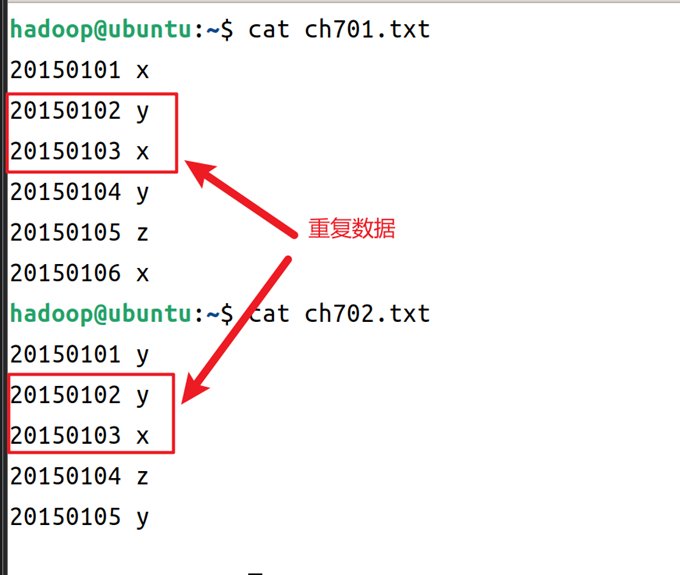
2.在家目录下创建两个输入源文件,这里以ch701.txt和ch702.txt,两个文件内容可以在实验指导书中获取,也可以自己自定义文本内容,从实验指导书获取的文本如图2所示。
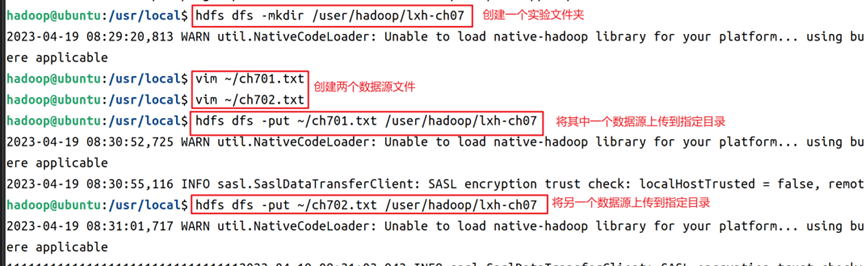
3.在hdfs上创建本例实验文件夹,然后将两个文件上传到实验文件夹内,操作命令如图3所示。
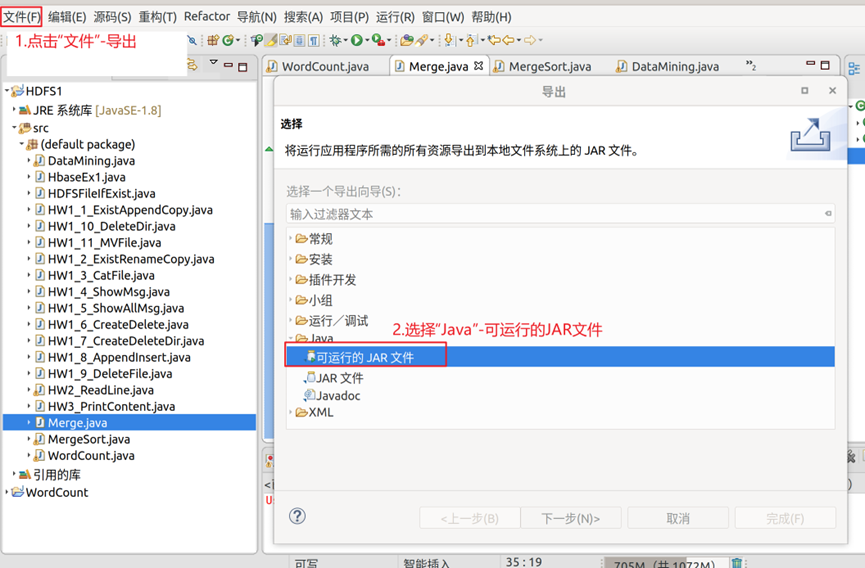
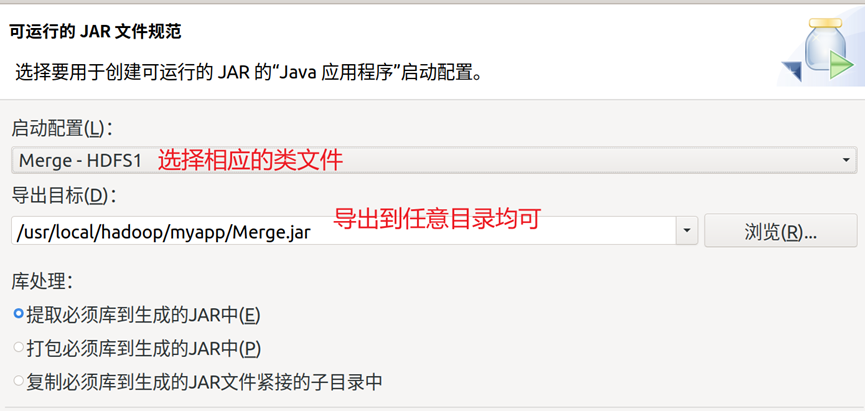
4.创建名为Merge的类文件,代码可以从实验指导书中获取,编译完成后导出为可运行的JAR文件,导出操作步骤如图4-图5所示,导出完成后,使用hadoop的jar命令调用相应的jar包进行数据处理,命令如图6所示。

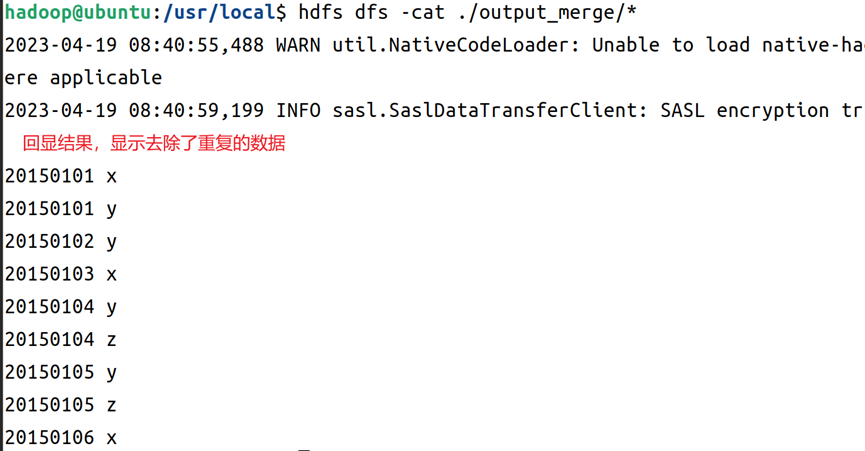
5.执行完成后,在hdfs上使用cat命令回显输出结果的文件夹,显示已经成功去除了重复的数据项,如图7所示。
6.接下来的内容为Java API编程实现对输入文件的排序。
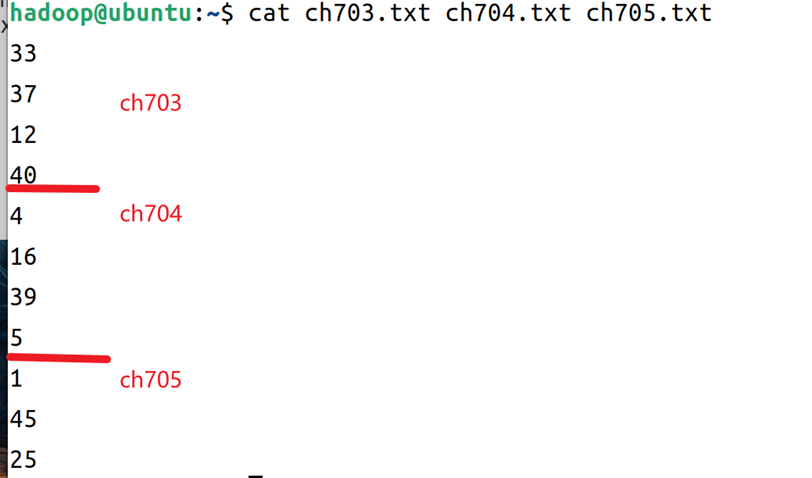
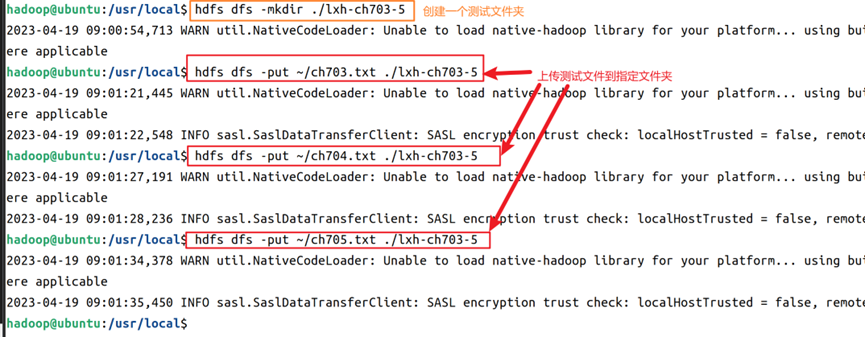
7.在家目录下创建三个输入源文件,这里以ch703.txt、ch704.txt、ch705.txt为例子命名,三个文件内容可以在实验指导书中获取,也可以自己自定义文本内容,从实验指导书获取的文本如图8所示。
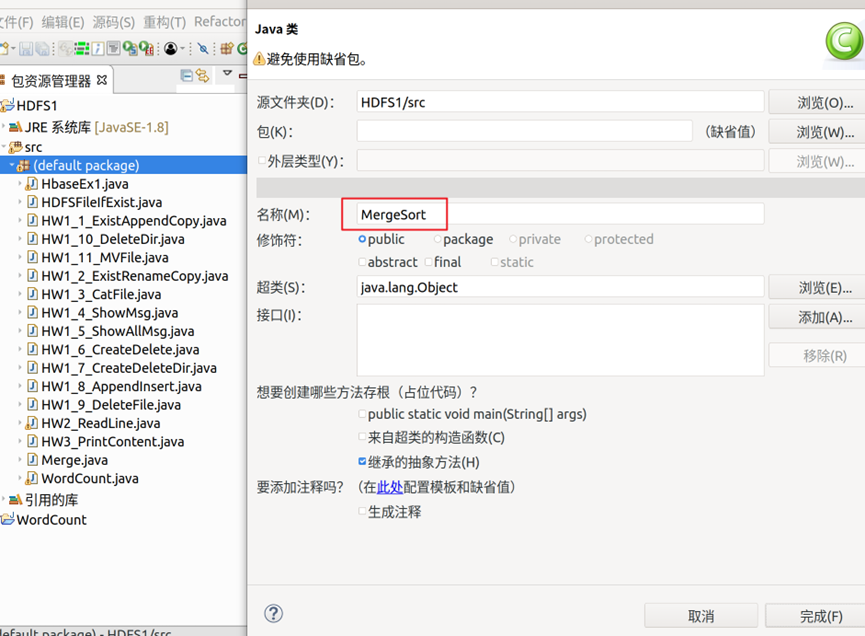
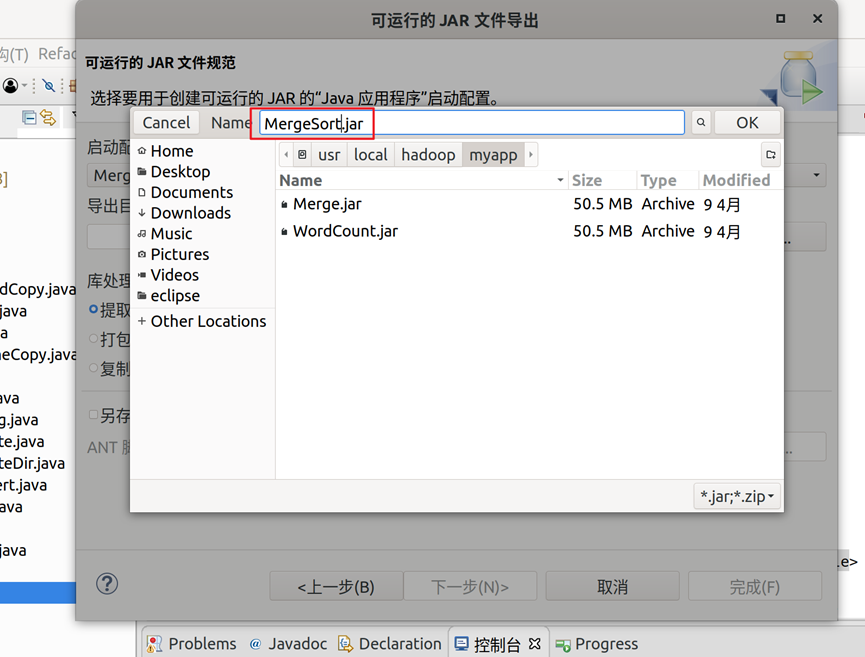
8.创建名为MergeSort的类文件,如图9所示;代码可以从实验指导书中获取,编译完成后导出为可运行的JAR文件,导出操作步骤可参考图4-图5的内容,导出结果界面如图10所示。
9. 在hdfs上创建本例实验文件夹,然后将三个文件上传到实验文件夹内,操作命令如图11所示;导出完成后,使用hadoop的jar命令调用相应的jar包进行数据处理,命令如图12所示。
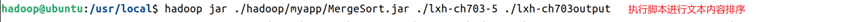
10.执行完成后,在hdfs上使用cat命令回显输出结果的文件夹,显示已经成功进行文本排序操作,如图13所示。
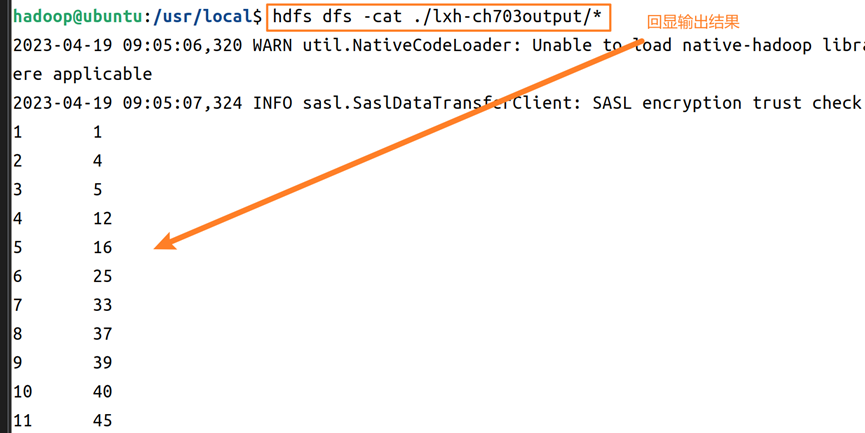
11.接下来的内容为Java API编程实现对给定的表格进行信息挖掘。
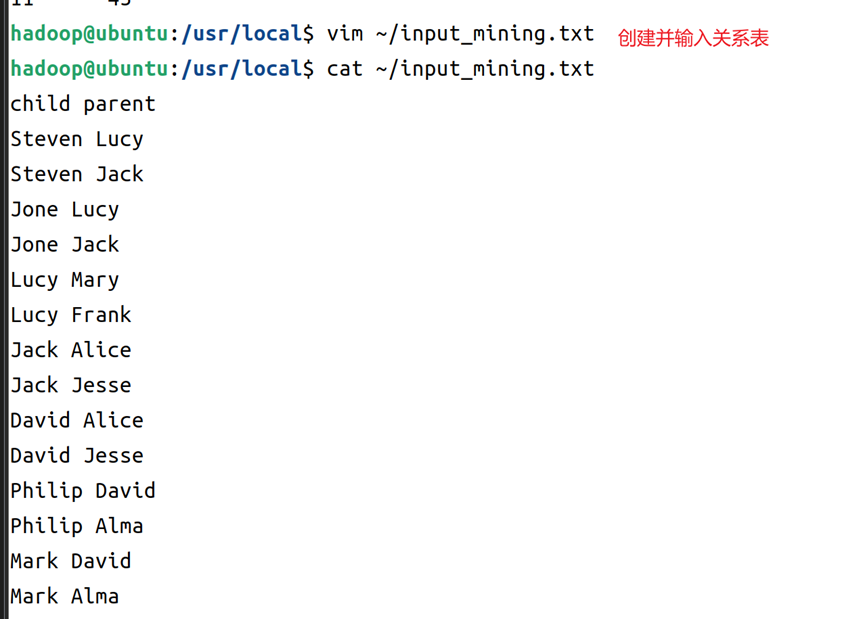
12.在家目录下创建输入源文件,这里以input_mining.txt为例子命名,文件内容可以在实验指导书中获取,也可以自己自定义文本内容(满足类似child parent格式需求就可以了),从实验指导书获取的文本如图14所示。
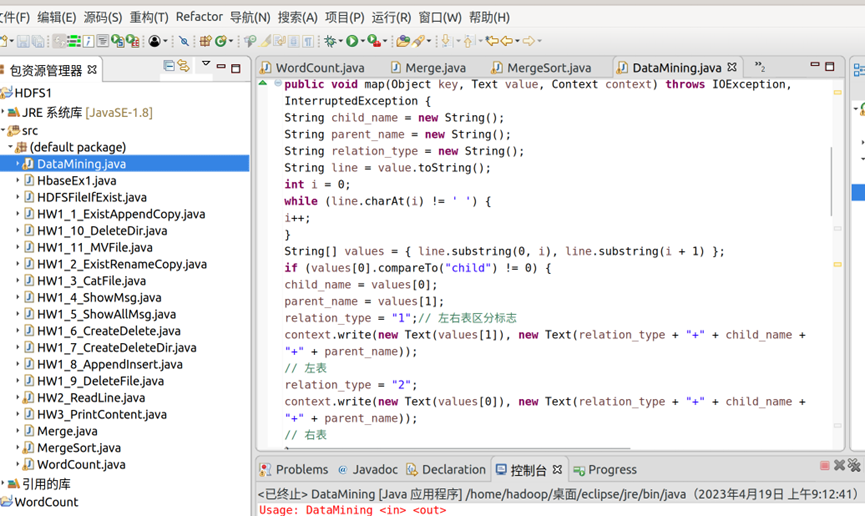
13.创建DataMining类文件,大致代码如图15所示,文件的导出打包可以参见本例前序步骤。
14.在hdfs上创建本例实验文件夹,然后将文件上传到实验文件夹内,操作命令如图16所示;导出完成后,使用hadoop的jar命令调用相应的jar包进行数据处理,命令如图17所示。


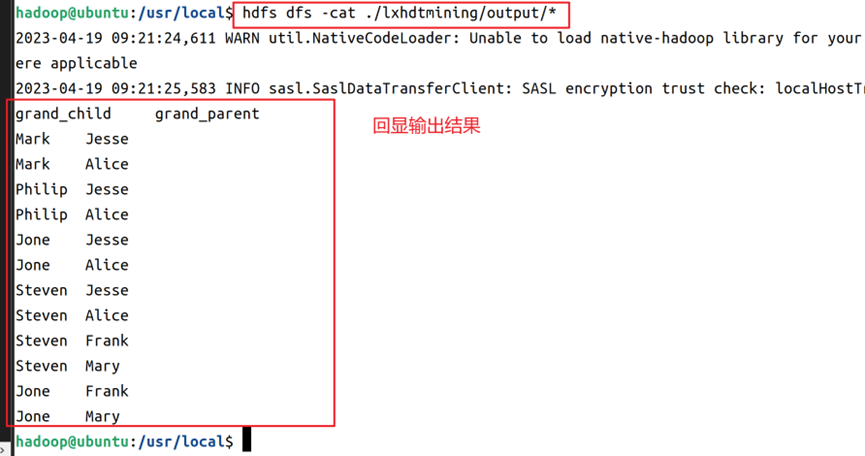
15.执行完成后,在hdfs上使用cat命令回显输出结果的文件夹,显示已经成功进行了数据关系挖掘,如图18所示。
附件下载
微信扫描下方的二维码阅读本文
