
写在前面:本文教程图片和描述文字(除部分文字外)为李星海创作。配置均在实机进行。
本教程适用于【广州商学院】【2020级】【信息技术与工程学院】【计算机科学与技术(专升本)】【2022-2023学年第2学期】《大数据应用技术》课程环境。
参考资料:
Hadoop3.1.3安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04)
Ubuntu (Kylin) 16.04 换源阿里云_ubuntukylin源_Pou光明的博客-程序员宝宝
0.前置准备环境:将提供的软件安装包下载到本机,本教程中以放到D盘的【DSJSOFT】文件夹为例,如图1所示。
1.在VMware新建虚拟机,读取文件夹下的ubuntukylin安装镜像文件,如图2所示。
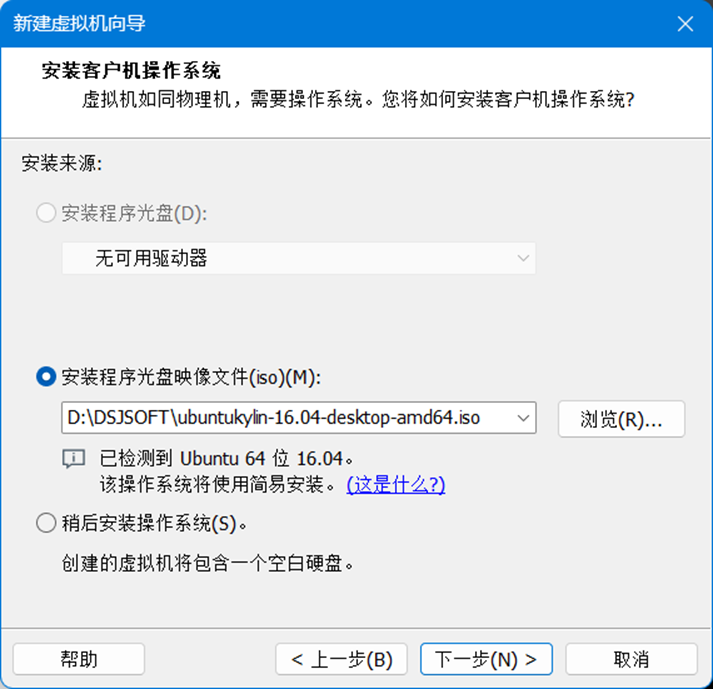
2.指定Linux全名,用户名,密码(密码为jk2005),如图3所示。
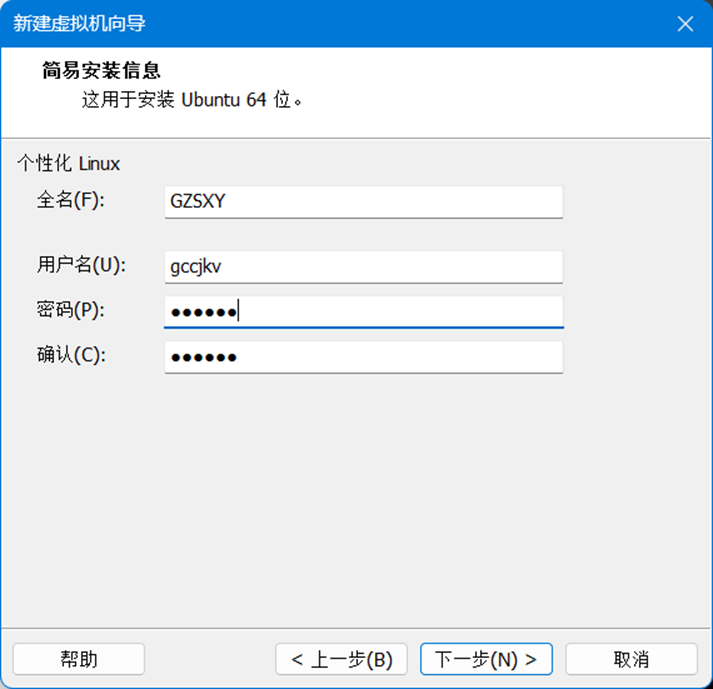
3.指定安装大小,这里建议40G,如图4所示。
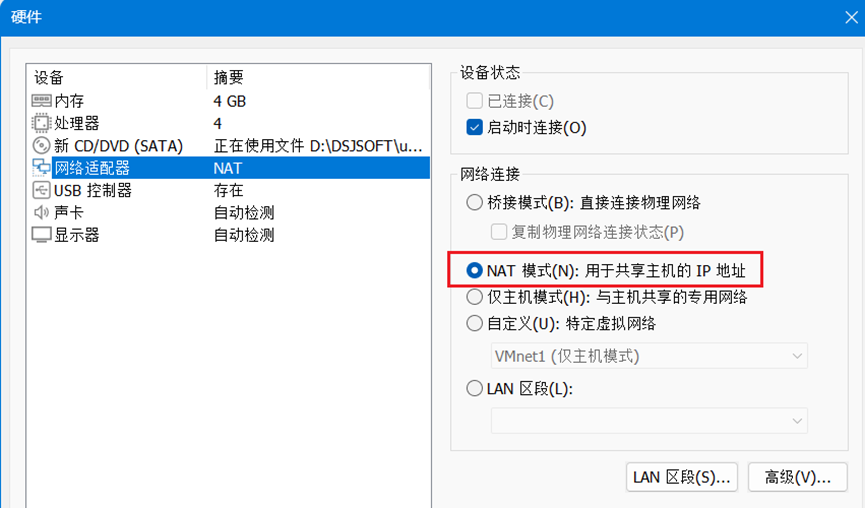
4.确保网络适配器处于“NAT”模式,如图5所示。
5.进入安装过程,此处等待20分钟左右,耐心等就好,会自动进入桌面,如图6所示。
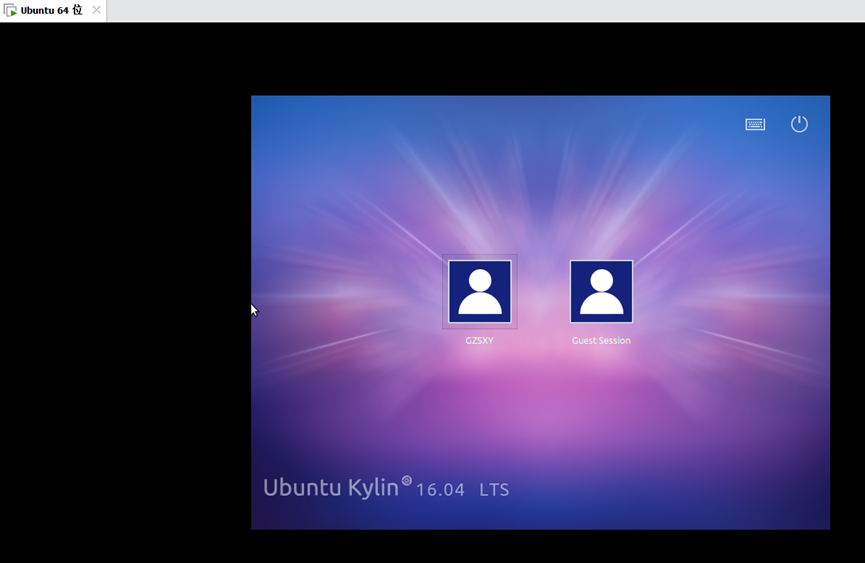
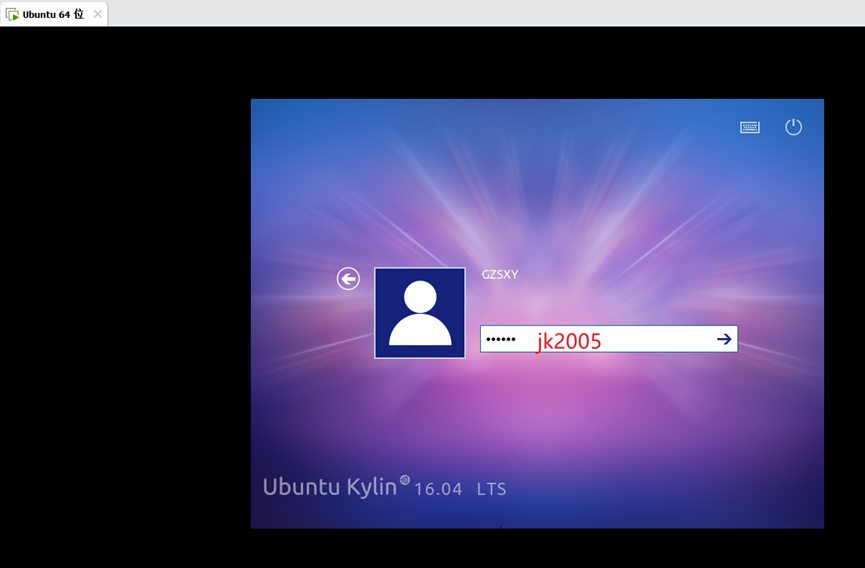
6.完成安装之后,就显示了刚刚创建的账户,通过点击GZSXY进行登录,如图7-图8所示。
7.指定root账户密码,如图9所示。
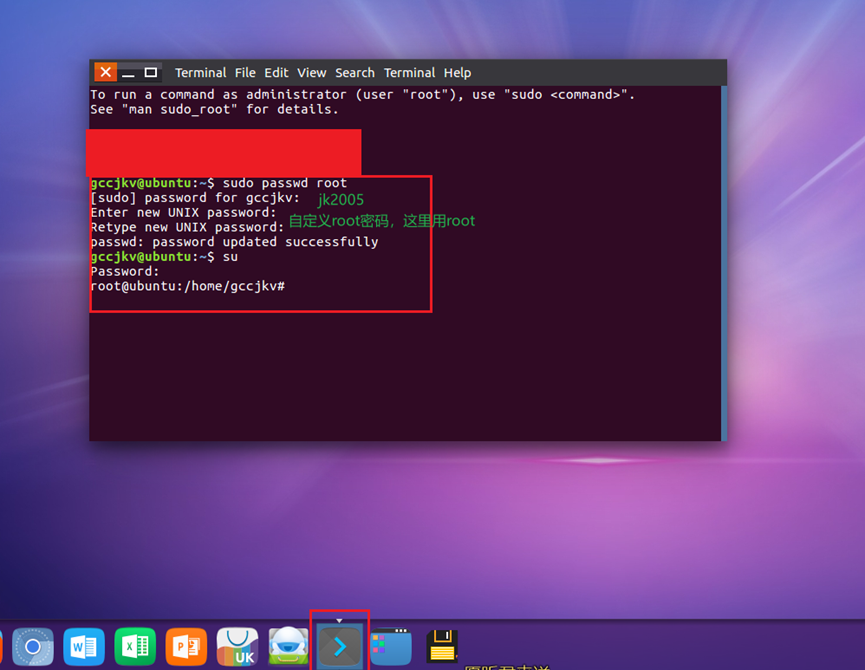
8.设置系统环境为中文,在终端输入指令 dpkg-reconfigure locales,使用tab切换到语言选项界面,找到en_us.utf-8 使用【空格】将*号取消。如图10所示。
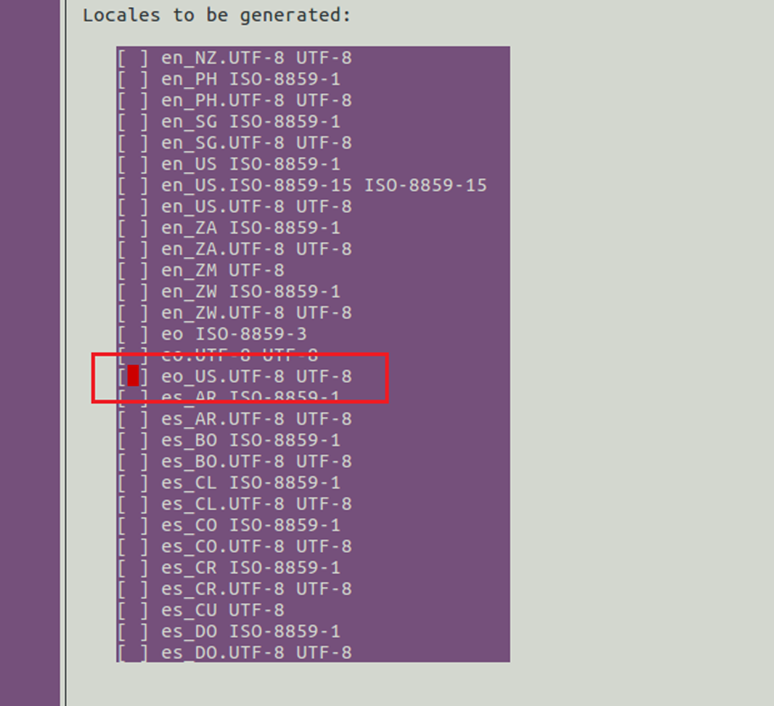
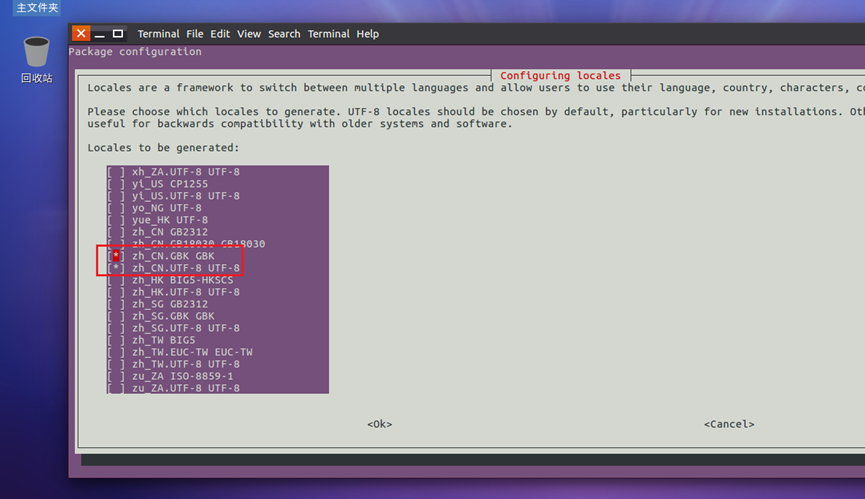
9.找到zh_cn.gbk 和zh_cn.utf-8,使用【空格】选中,如图11所示。
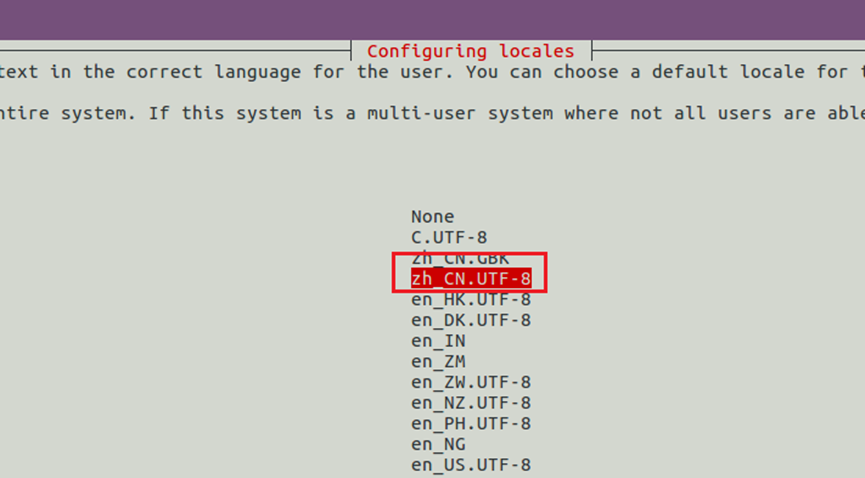
10.完成后,使用tab切换到<ok>,按【enter】,进入下一界面,使用↑↓找到【zh_cn.utf-8】按【enter】选中,如图12所示。
11.重启虚拟机,使配置生效
12.重启之后,在弹出的软件源更新提示选择【不更新】,同时为了配置方便,在文件夹命名选项选择【keep old names】。如图13所示
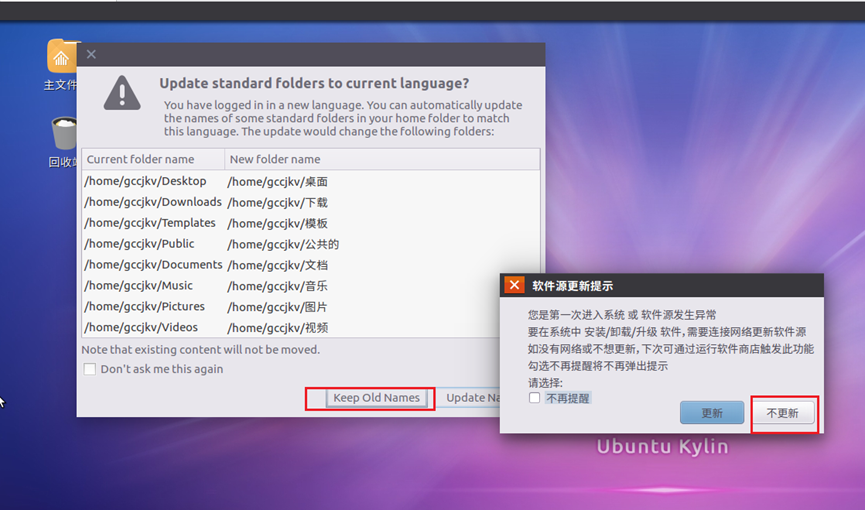
13.先使用【apt update】更新源,然后使用【apt install vim】安装vim编辑器,这里使用默认源,如图14所示。
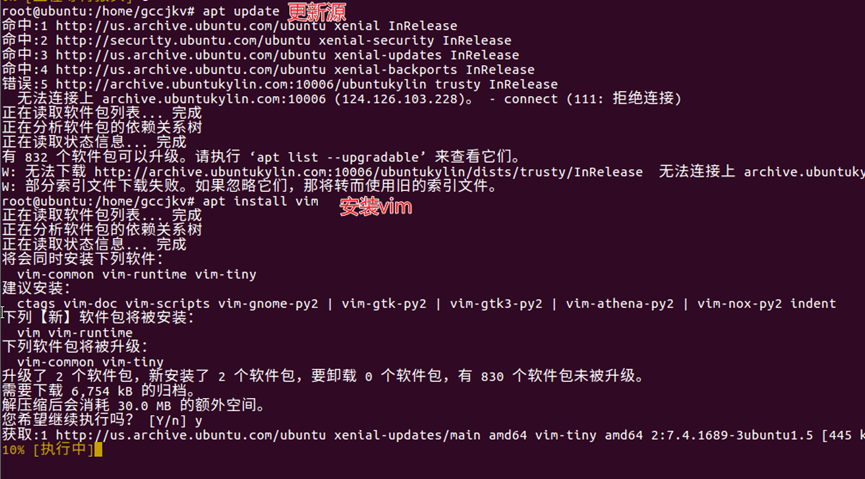
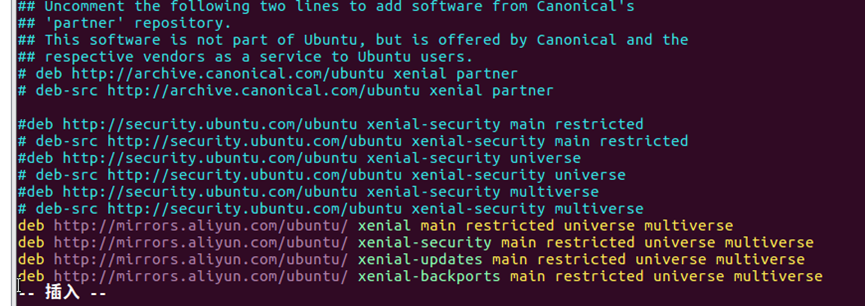
14.完成vim编辑器的安装后,进行换源操作:输入【vim /etc/apt/source.list】,编辑源文件,将原有源使用【#】注释或者删除全部内容,然后将阿里云源粘贴到文件中。
deb http://mirrors.aliyun.com/ubuntu/ xenial main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ xenial-backports main restricted universe multiverse
15.对于14步的操作,完成后的源文件内容如图15所示。
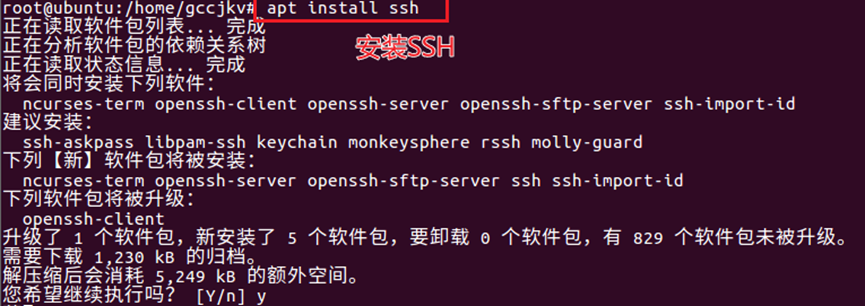
16.使用【apt update】命令更新源,然后输入【apt install ssh】安装ssh服务,如图16所示。
17.添加hadoop用户,使用【useradd -m hadoop -s /bin/bash】完成新建hadoop用户,使用【passwd hadoop】设置密码,使用【adduser hadoop sudo】将其添加到管理员组,命令操作过程如图17所示。
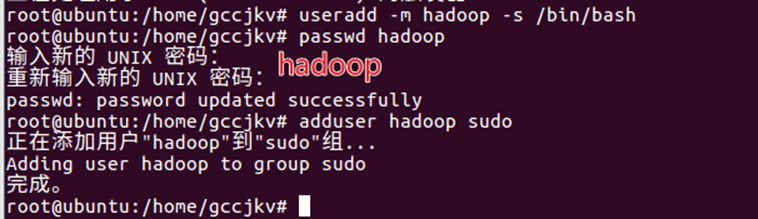
18.使用【su hadoop】或切换用户方式(推荐),切换到hadoop用户后,使用【ssh localhost】完成ssh初次启动,通过命令【cd ~/.ssh/】【ssh-keygen -t rsa】【cat ./id_rsa.pub >> ./authorized_keys】添加自动登录,如图18所示。
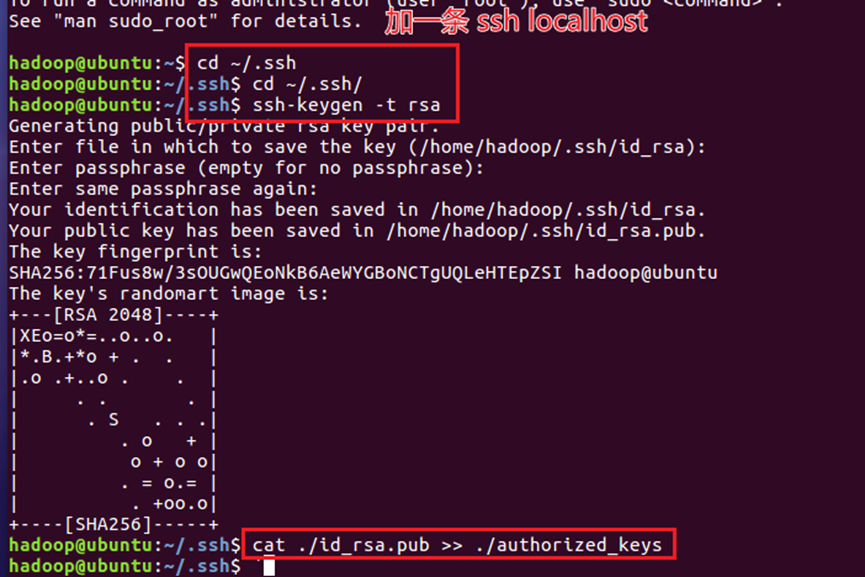
19.通过【ifconfig】查看虚拟机IP地址。使用Xshell软件对其进行连接,配置界面如图19所示。
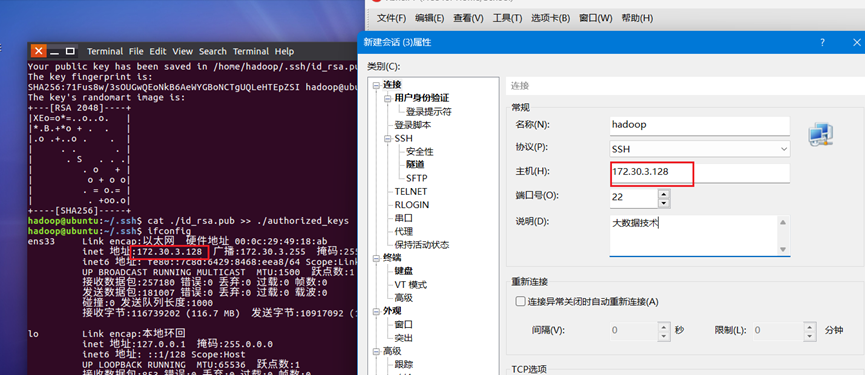
20.点击图19的【连接】按钮后,弹出用户名和密码,这里输入创建的hadoop用户及密码,如图20-21所示。
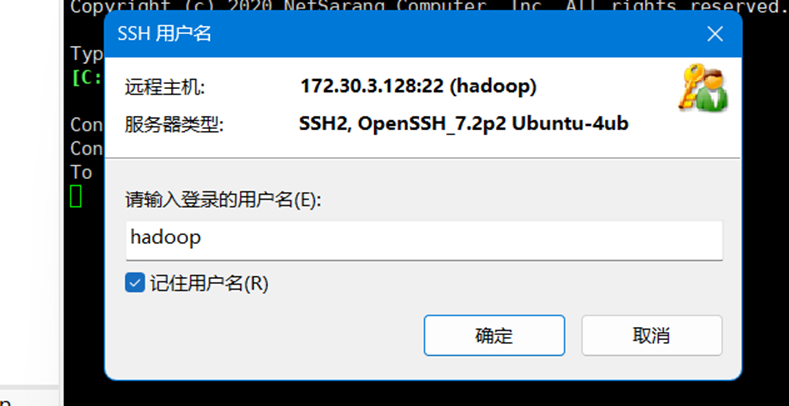
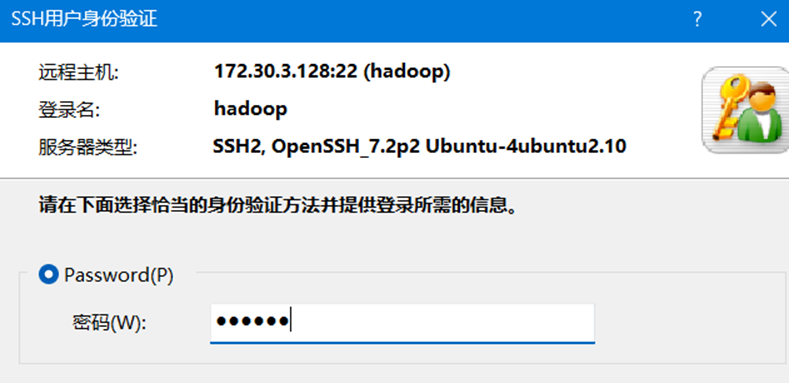
21.如果输入内容都正确,则此时会连接上Ubuntu,终端显示为hadoop用户,如图22所示。
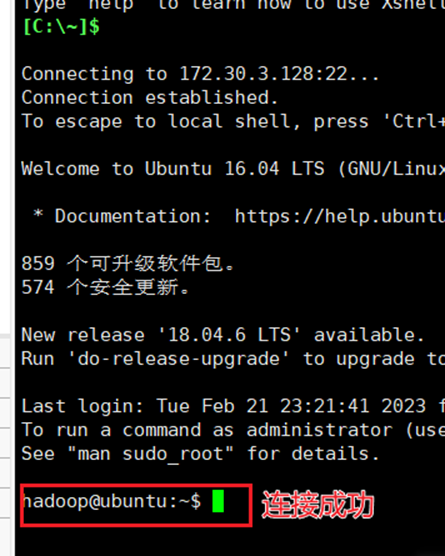
22.将图1中的【tar.gz】后缀复制到hadoop的家目录下,然后使用
- cd ~
- tar -zxf hadoop-3.1.3.tar.gz -C /usr/local
- cd /usr/local/
- mv ./hadoop-3.1.3/ ./hadoop
- chown -R hadoop ./hadoop
命令解压并配置hadoop,如图23所示。
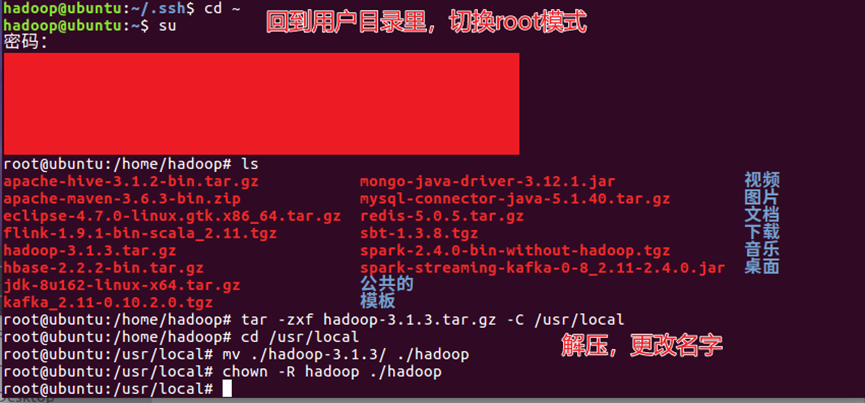
23.将目录切换到【/usr/lib】下,创建存放JDK的文件夹,返回主目录,解压JDK文件到存放JDK的文件夹下,命令组如下所示,操作过程如图24所示。
- cd /usr/lib
- mkdir jvm
- cd /home/hadoop
- tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm
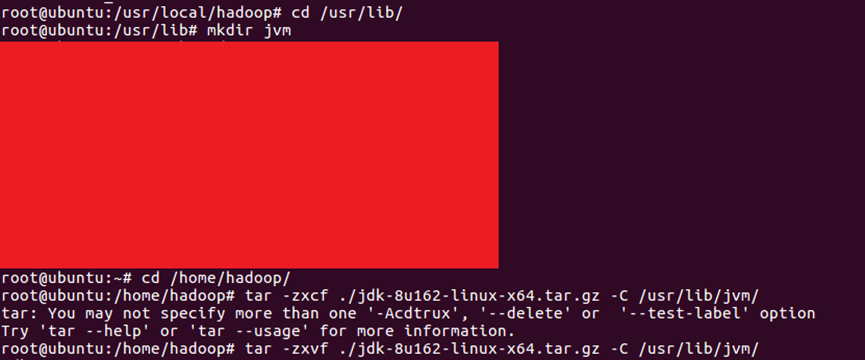
24.使用【vim ./.bashrc】编辑bashrc文件,在头部空行增加如下内容,完成结果如图25所示。
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native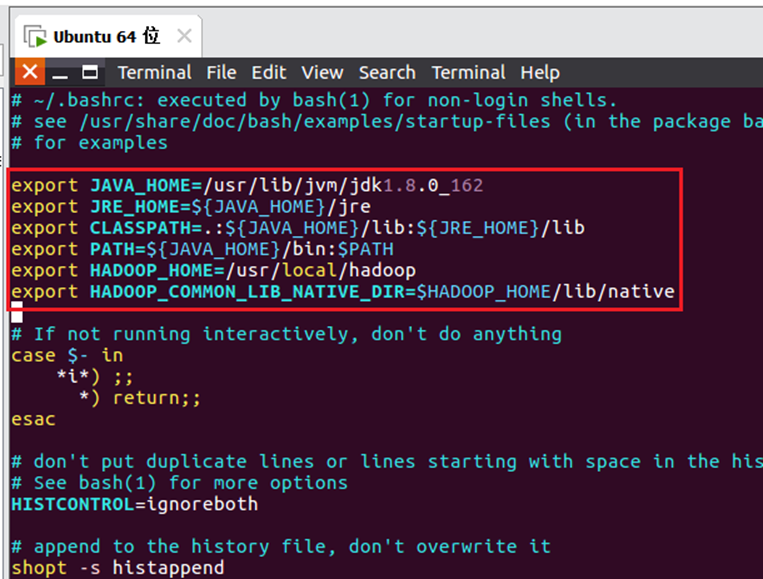
25.使用source ~/.bashrc 编译文件,然后通过输入【java -version】查看java版本,如果之前的步骤都正确进行,可以显示java版本号,如图26所示。

26.切换到hadoop目录,使用【./bin/hadoop version】查看hadoop版本,如果前面的步骤均正确配置,可以显示hadoop的版本号,如图27所示。

27.通过运行grep实例,将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中,如图28所示。

28.执行成功后显示dfsadmin出现了一次,如图29所示。

29.下面通过配置xml文件对Hadoop进行伪分布式配置
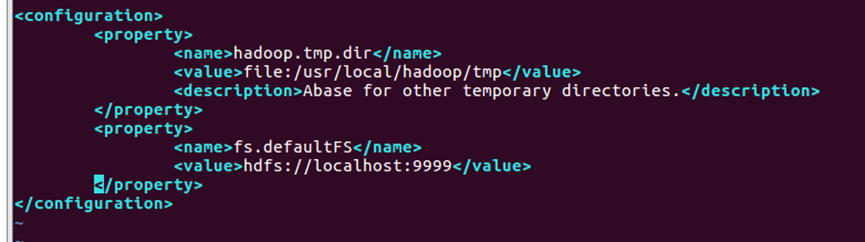
30.Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。使用命令【vim ./etc/hadoop/core-site.xml】修改配置文件 core-site.xml,修改结果如图30所示。
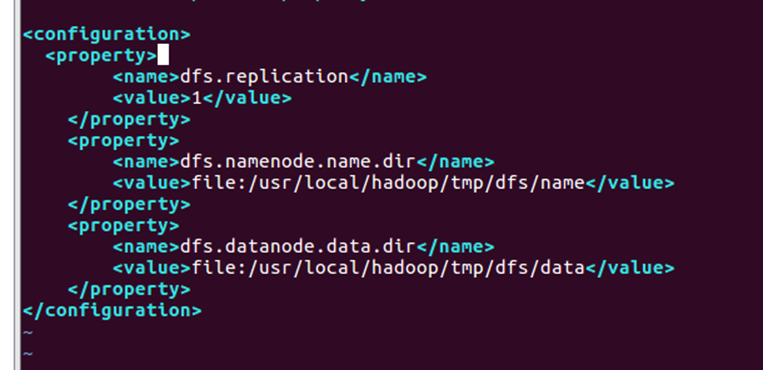
31.使用命令【vim ./etc/hadoop/hdfs-site.xml】修改文件,修改结果如图31所示。
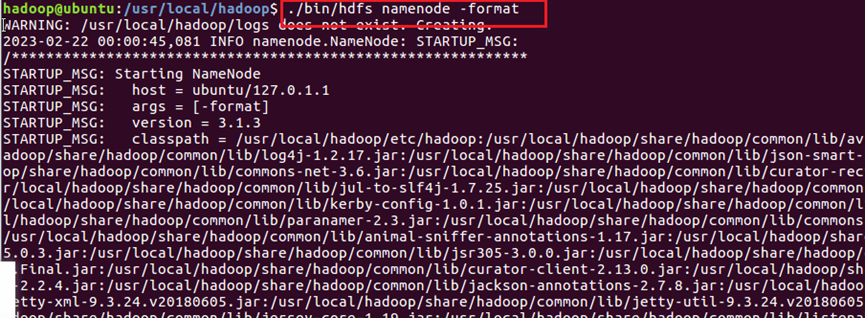
32.执行NameNode格式化,如图32所示。
33.使用命令【./sbin/start-dfs.sh】开启namenode和datanode守护进程,结果如图33所示。

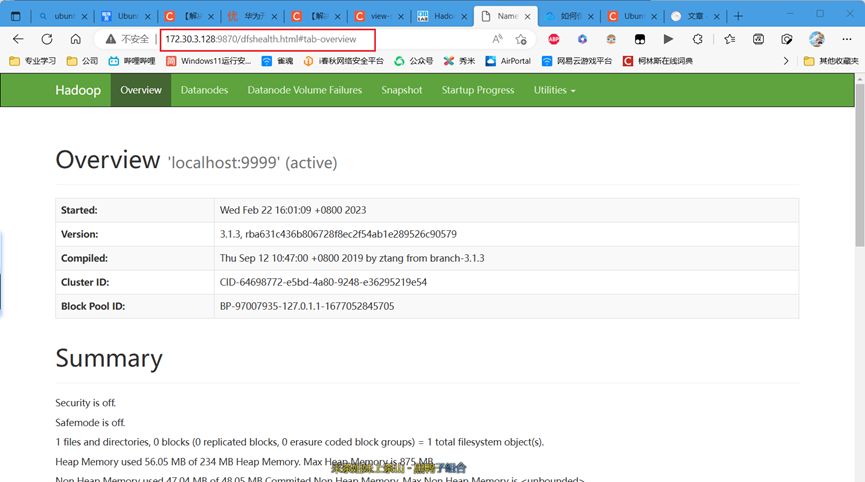
34.可以通过浏览器访问【http://虚拟机地址:9870】查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。如图34所示。
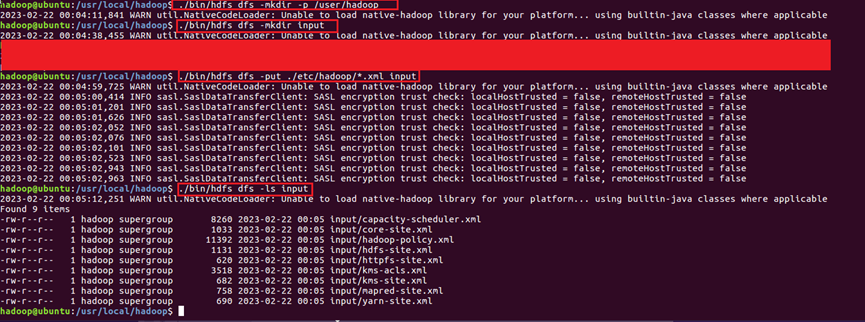
35.要使用 HDFS,首先需要在 HDFS 中创建用户目录【./bin/hdfs dfs -mkdir -p /user/hadoop】,接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input【./bin/hdfs dfs -mkdir input 】【./bin/hdfs dfs -mkdir input】。复制完成后,可以通过【./bin/hdfs dfs -ls input】命令查看文件列表,命令过程如图35所示。
36.通过执行hadoop伪分布式运行,对结果再次进行验证,命令如下所示,结果如图36所示。
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'

37.将结果取回本地的./output目录,并使用cat命令进行显示,操作过程和结果如图37所示。

38.使用【./bin/hdfs dfs -rm -r output】 删除 output 文件夹,使用【./sbin/stop-dfs.sh】停止hadoop,使用【./sbin/start-dfs.sh】启动hadoop(要求在hadoop安装目录下),如图38所示。

39.此处开始是配置Eclipse,因为不算难,所以放到一起来写。
40.解压Eclipse软件,然后在刚刚创建的【/usr/lib/jvm/jdk1.8.0_162/jre/bin】目录下将jre复制到eclipse的jre中,双击eclipse齿轮图标,即可正常启动。如图39所示。

环境配置可以提供技术支持和指导:
对于【计科2005】班:免费完全技术支持
对于【其他】班:免费有限技术支持或付费完全技术支持
微信扫描下方的二维码阅读本文

还行
不错喵
还行
不错喵