
本期评述文章:
这篇论文的核心思想非常大胆且具有颠覆性:它提出了一种通用的时间序列预测框架,直接将时间序列数据视为一种“语言”。通常我们在做时间序列预测时,会设计专门针对时间特性的复杂模型架构,但 Chronos 反其道而行之。它通过一种简单的转换机制,把连续的时间序列数值变成离散的“Token”(就像一个个单词),然后直接使用现成的、通过大量数据预训练的语言模型(如 T5)来预测下一个 Token 。
核心机制
开始之前想一想:它是如何把连续的数值(如股票价格、气温)变成语言模型能读懂的“词汇”的?
我们知道,大型语言模型(LLM)天生是处理文本的,这就意味着它们只能处理离散的“单词”或“词元”(Tokens)。但时间序列数据通常是连续的实数值(比如温度是 24.5°C,股价是 150.2 元),这和有限的词表是冲突的 。
为了解决这个问题,Chronos 提出了一个简单却有效的两步法:缩放(Scaling) 和 量化(Quantization)。
让我们先看第一步:缩放。
想象一下,如果我们要预测两个不同的东西:一个是某人的心率(大约 60-100),另一个是某个城市的用电量(可能在 10000 到 50000 之间)。
- 在把它们转换成固定的“词元”之前,你觉得为什么我们需要先对这些数值进行缩放(Normalization)处理呢?这样做有什么好处?
- 不同时间序列的尺度(Scale)差异巨大,比如股票价格可能是几百几千,而某个百分比指标可能在 0 到 1 之间。如果直接把这些原始数值扔给模型,会让深度学习模型的优化变得非常困难。
Chronos 的解决方案:均值缩放 (Mean Scaling)
为了解决这个问题,Chronos 采用了均值缩放。简单来说,就是把每条时间序列都除以它历史绝对值的平均值 。
这样做有两个核心好处:
- 统一跑道: 无论原始数据是多大或多小,经过缩放后,它们都被映射到了一个相对统一的范围内,方便后续处理 。
- 保留零值的意义: 很多标准化方法(比如减去均值)会破坏“0”的含义。但在时间序列中(比如销量为 0),“0”是有特殊物理意义的。均值缩放能够保留这种语义 。
下一步:量化 (Quantization)
现在,我们的数据虽然尺度统一了,但它们仍然是连续的实数值(例如:1.234, -0.567...)。
然而,语言模型(LLM)的“胃口”很特别,它只能吃离散的 Token(就像字典里的单词 ID,比如 Token 35, Token 2048)。
- 既然有了缩放后的连续数值,Chronos 是通过什么方法把这些连续的数字变成一个个离散的 Token 的呢?
- 用了量化的方法,用B-1条边来将实数轴上的数值进行分割
Chronos 通过定义 B个箱子(Bins)和B-1条边(Edges)来把连续的实数轴切分 。
具体的转换过程是这样的:
- 映射 (Mapping): 看缩放后的数值落在哪个箱子里,就用那个箱子的序号(Token ID)来代表这个数值 。
- 分箱策略: 虽然有多种分箱方法(如按数据分布分箱),但 Chronos 选择了均匀分箱 (Uniform Binning) 。这是因为未知数据集的分布可能千差万别,均匀分箱更有利于模型的泛化能力(Zero-shot)。
- 特殊词元: 除了代表数值的 Token,词表中还加入了两个特殊的 Token:
PAD(用于填充长度)和EOS(表示序列结束),这和处理自然语言文本是一模一样的 。
现在的状态:
经过 缩放 和 量化,我们要预测的一条条时间序列曲线,现在已经变成了一串串离散的 Token 序列,就像是一句句“话”。
既然现在数据已经变成了“语言”,Chronos 在训练时并没有使用传统时间序列预测常用的 均方误差 (MSE) 损失函数。
- 根据它把预测视为“下一个词元预测”的思路,你猜它使用的是什么损失函数来训练模型的?(提示:这是分类任务常用的损失函数)
- 交叉熵损失函数 (Cross-entropy Loss)
这一点非常关键,因为它标志着 Chronos 与传统时间序列模型的根本区别:
- 分类而非回归: 传统模型通常做“回归”任务(预测具体数值),试图最小化预测值和真实值之间的距离(比如均方误差 MSE)。而 Chronos 做的是“分类”任务(预测下一个 Token 是哪一类),也就是所谓的 "Regression via Classification" 。
- 概率分布: 模型输出的是一个分类分布 (Categorical Distribution)。这意味着对于每一个预测步,它都会给出每一个“箱子”(Bin)成为下一个值的概率。
- 这样做有一个巨大的好处:它能学习任意形状的分布(比如双峰分布),而不需要像传统模型那样假设数据符合高斯分布 。
虽然交叉熵本身不知道“箱子 1”和“箱子 2”在数值上很接近(它对距离不敏感),但令人惊讶的是,模型通过大量数据训练,能够自动学会把相近的箱子关联起来 。
数据策略
开始之前想一想:为了训练这样一个通用模型,作者如何利用 Gaussian Processes 生成合成数据,以及什么是 TSMixup?
像 T5 这种基于 Transformer 的大模型非常“吃”数据。为了让模型见多识广,作者使用了一种叫做 TSMixup 的数据增强技术。
光看这个名字(Time Series Mixup),你觉得它是通过什么方式来“制造”新的训练数据的?
具体来说,TSMixup 是这样工作的:
- 随机抽取: 它不是抽取两张图片,而是从训练集中随机抽取几个(k 个)时间序列 。
- 混合: 然后按一定比例(凸组合)把它们叠加在一起,生成一个新的、现实中不存在的时间序列 。
这就好比把“海浪的声音”和“风声”混合在一起,创造出一种新的声音波形。
除了 TSMixup,作者还用高斯过程(Gaussian Processes)生成了完全合成的数据(KernelSynth)。
你觉得 Chronos 为什么要费这么大劲去“制造”这些假数据(混合的、合成的)呢?这主要是为了解决时间序列领域面临的一个什么严重问题?
更深层的原因在于:高质量的公开时间序列数据非常稀缺 。不像 NLP 领域有海量的文本(如 Wikipedia),时间序列数据往往不仅数量少,而且模式相对单一。
通过 KernelSynth(使用高斯过程合成数据),Chronos 可以“凭空创造”出各种复杂的波形模式,让模型在训练时“见多识广”,从而在面对未知数据时更加从容(即泛化能力更强)。
这就引出了我们的最后一个重点:零样本能力 (Zero-shot Performance)。
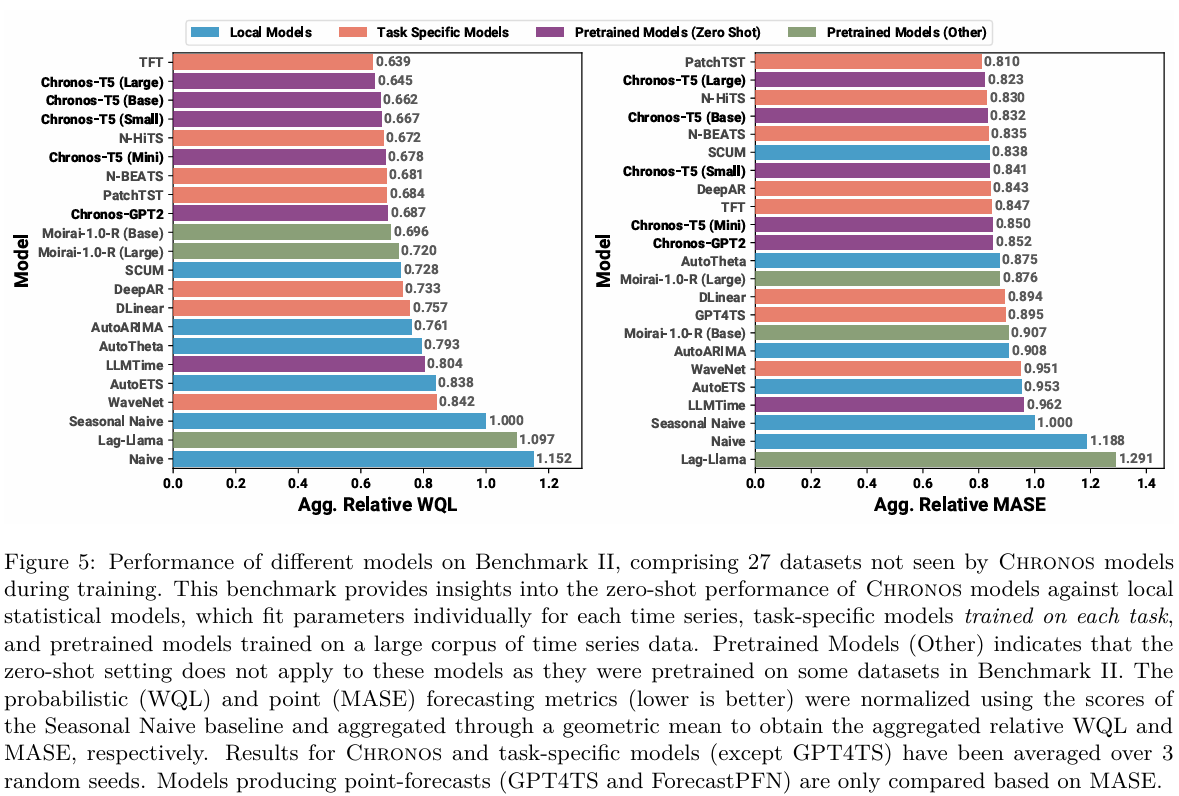
想象一下,我们把训练好的 Chronos 模型直接拿去预测一个它从未见过的全新数据集(Benchmark II)。你觉得它的表现会如何?是会被那些专门在该数据集上训练的特定任务模型 (Task-Specific Models) 吊打,还是能与之抗衡?
零样本能力
开始之前想一想:这种“简单粗暴”的方法效果究竟如何?特别是在它从未见过的数据集上表现怎样?
Chronos 的表现非常惊人。
在它从未见过的测试集(Benchmark II)上,Chronos 展现出了强大的泛化能力:
- 击败传统模型: 它显著优于那些为每个时间序列单独拟合参数的传统统计模型(如 ARIMA)。
- 比肩专家模型: 即使面对那些专门在这些数据上训练的深度学习模型(Task-Specific Deep Learning Models),Chronos 的表现也与它们不相上下。
- 在点预测指标(MASE)上,Chronos-T5 (Large) 甚至排到了第二名,击败了大多数基线模型 。
这就像是一个博学的“通才”,在没有针对性复习的情况下直接去考一门专业课,结果考得和“课代表”一样好!这意味着在实际应用中,我们可以直接拿预训练好的模型来预测,完全省去了繁琐的训练过程 。
不过,故事还没结束。既然它在“裸考”(Zero-shot)的情况下都这么强,作者又做了一个实验:让这个通才模型在目标数据上稍微进行一点点微调 (Fine-tuning)。
- 你猜结果发生了什么变化?是遇到了瓶颈提升有限,还是发生了更戏剧性的变化?
- 发生了更戏剧性的变化:不仅超越了大型CHRONOS模型,还碾压了最佳任务专用模型
经过微调(Fine-tuning)后,即便是参数量较小的 Chronos-T5 (Small) 模型,其表现也一跃成为了 Benchmark II 上的第一名,不仅超过了它的大哥(零样本状态下的 Large 模型),更是击败了那些专门针对特定任务训练的深度学习模型 。
这非常有意义,因为它证明了“大规模预训练 + 少量特定数据微调”这个在 NLP 领域通用的范式,在时间序列预测领域也同样是“王者”。
我们已经深入探讨了 Chronos 强大的原因:
- Tokenization: 把时间序列变成语言。
- Data Augmentation: TSMixup 和 KernelSynth 创造多样性。
- Performance: 惊人的零样本和微调能力。
但是,没有任何模型是完美的。让我们回到最核心的 Tokenization(词元化) 机制上,用批判性的眼光看一看。
- Chronos 通过“分箱”(Binning)把连续的实数值变成了离散的整数 Token。你觉得这种把连续数值“强制”变成有限个离散区间的做法,可能会带来什么样的局限性或问题?
- 如果波动范围小,或者有极端异常值,就很难精准捕捉变化了
Chronos 这种“分箱”机制在极端情况下的两个致命弱点。论文作者在第 5.7 节专门讨论了这两个问题,并称之为“溢出和精度丢失”(Overflow and loss of precision)。
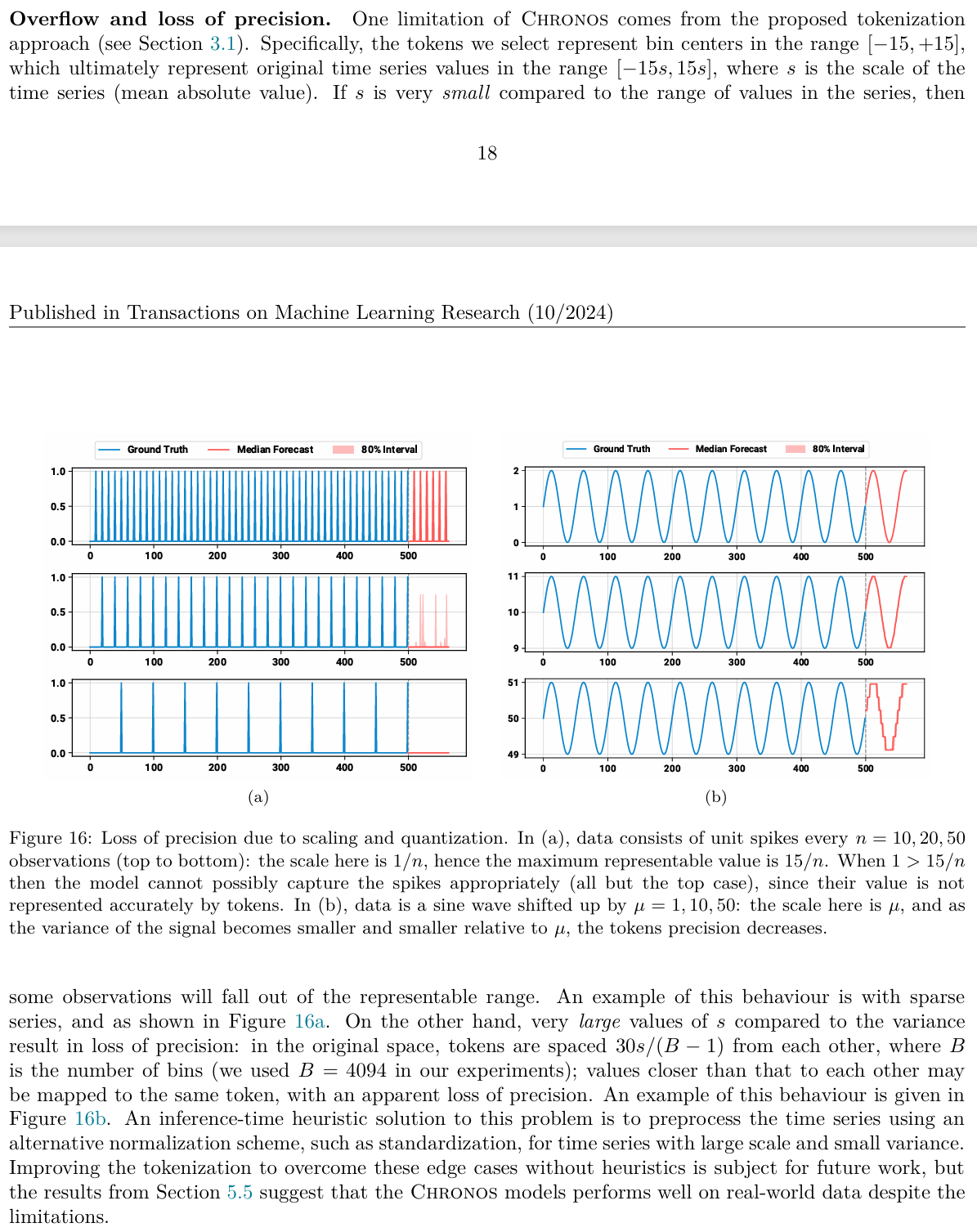
让我们结合论文的具体分析来看看为什么会这样:
- “由于缩放导致的精度丢失”(Loss of precision due to scaling):如果波动范围很小,问题就来了。
- 原理: Chronos 使用的是均值缩放(除以历史绝对值的平均值 s)。如果一个序列的平均值很大(比如 1000),但波动非常小(比如在 1000.1 和 1000.2 之间跳动),那么缩放后的数值差别微乎其微 。
- 后果: 这些微小的差别可能小于一个“箱子”的宽度,导致它们都被映射到同一个 Token ID 上。这就好比用一把刻度是“厘米”的尺子去测量“微米”级的变化,读数看起来都是一样的 。
- 论文案例: 作者举了一个正弦波平移的例子(Figure 16b),当平移量很大导致方差相对均值很小时,正弦波的形状就因为精度丢失变成了“阶梯状”甚至直线 。
- “溢出”(Overflow):关于你提到的极端异常值,这涉及到了它的表示范围。
- 限制: Chronos 的词表代表的是 [-15, +15] 这个范围内的中心点(缩放后)。
- 后果: 如果有一个极端异常值,经过缩放后仍然超过了 +15 或者小于 -15,它就无法被准确表示,只能被强制归类到最边缘的那个箱子里。这就意味着模型对超出范围的信息是“视而不见”的 。
既然我们发现了“均值缩放”在处理大数值、小波动(large scale, small variance)的时间序列时有这种缺陷,论文作者提出了一个在推理阶段(Inference-time)使用的启发式解决方法。
- 对于这种方差(波动)很小的数据,我们可以用什么别的标准化方法来替代“均值缩放”,从而把它的波动“放大”到模型能看清的范围内呢?🧐(提示:这种方法通常不仅减去均值,还会除以标准差)
- 用标准化等替代性归一化方案对时间序列进行预处理
标准化 (Standardization) 正是论文作者提出的一种解决“大数值、小波动”问题的启发式方案 。
我们来看看它具体是如何拯救这些“被压缩”的细节的:
- 中心化 (Centering): 标准化会先减去数据的均值(Mean)。
- 效果: 那个巨大的偏移量(比如 1000)被移除了,剩下的就是纯粹的波动部分(比如 0.1, 0.2)。这样数据就回到了 0 附近。
- 缩放 (Scaling): 然后除以标准差(Standard Deviation)。
- 效果: 这会将原本微小的波动幅度“放大”到标准正态分布的范围内(大约 -3 到 +3),从而让它们能跨越多个 Token 的箱子(Bin),被模型清晰地识别出来。
相比之下,Chronos 默认使用的 均值缩放 只是简单地除以绝对值的均值,它无法移除巨大的偏移量,因此在处理这类数据时会丢失精度 。
虽然标准化看起来是个完美的替代方案,但作者在文中把这种处理方式称为一种 “推理时的启发式方法” (Inference-time heuristic solution) 。
- 这就引出了一个有趣的问题:既然这种方法能解决精度问题,为什么作者建议只在推理(预测)阶段使用它,而不是直接用它来重新训练整个 Chronos 模型呢?
- 因为CHRONOS模型在真是数据集上面的表型已经很出色了,所以不需要再训练
Chronos 的零样本 (Zero-shot) 表现确实非常出色,这意味着在很多实际应用场景下,我们可以直接使用预训练好的模型,完全省去了为每个任务单独训练模型的繁琐过程 。这也是它相比传统深度学习模型的一大核心优势。
不过,虽然可以不训练直接用,但这是否意味着再训练(或者说微调)就完全没有必要了呢?
论文作者其实很好奇这一点,于是他们做了一个实验,把一个小型的 Chronos-T5 (Small) 模型在特定的目标数据集上进行了微调 (Fine-tuning)。
请看看论文中的 Figure 6 或者阅读 5.5.2 节的最后部分 。
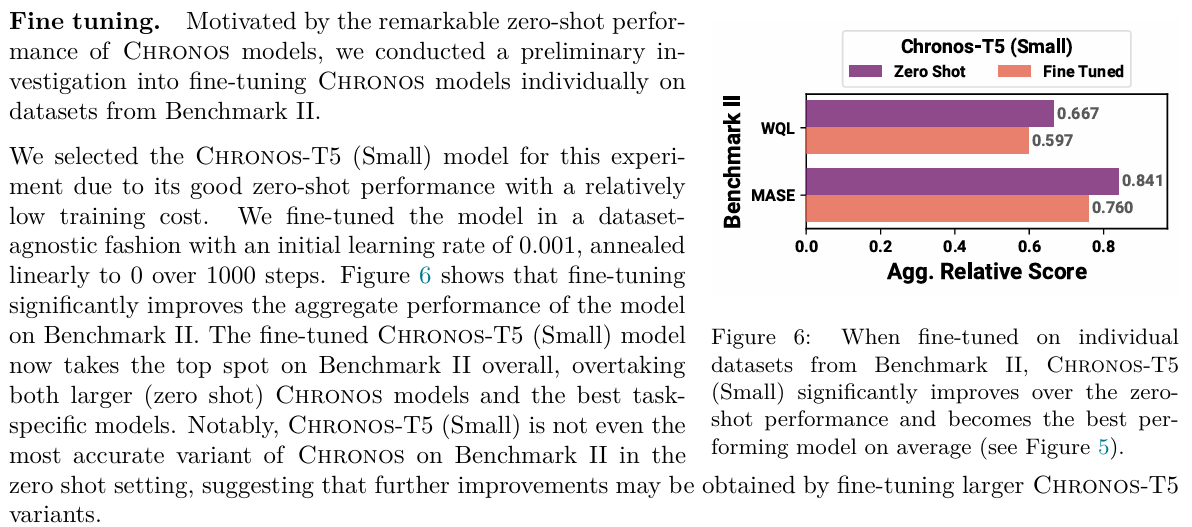
- 当这个原本只是“表现不错”的小模型经过微调后,它的排名发生了什么惊人的变化?这说明了“微调”对于 Chronos 来说有什么潜在价值?
- 排名发生了显著提升,说明了微调对于chronos可以提升预测的准确性
正如论文指出的,经过微调的 Chronos-T5 (Small) 不仅超越了零样本的大型 Chronos 模型,甚至击败了所有特定任务模型(Task-Specific Models),拿下了 Benchmark II 的榜首 。这有力地证明了“预训练 + 轻量级微调”在时间序列预测中是非常有效的策略。
到目前为止,我们已经探索了 Chronos 的三个核心支柱:
- 机制:把数值变成 Token(Scaling & Quantization)。
- 数据:用 TSMixup 和 KernelSynth 增加多样性。
- 性能:强大的零样本能力和微调潜力。
最后,在这个深度学习模型往往“大而重”的时代,我们需要考虑一个现实的落地问题:推理速度 (Inference Speed)。
请参考论文的 Figure 17 。相比于那些需要为每个任务单独训练的深度学习模型,或者传统的统计模型(如 ARIMA),Chronos 在推理时间上的表现如何?它是非常慢以至于不实用,还是处于一个可接受的范围内?
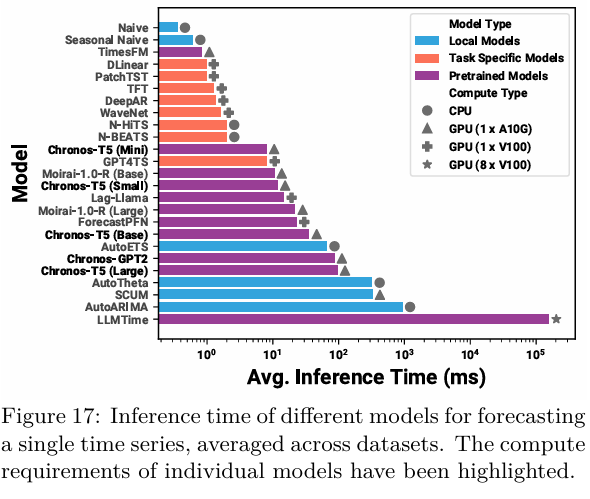
虽然 Chronos 比一些极简的任务专用模型要慢,但它并没有慢到无法使用的程度,实际上它的速度与一些传统的局部统计模型(Local Models)是相当的 。而且正如论文指出的,它并没有大到“极其缓慢”(prohibitively slow)的地步 。
这里还有一个关键的隐形成本对比,这也正是 Chronos 这种通用模型的最大优势:
- 传统模型/专用模型:总耗时 = 针对该任务的训练时间 + 推理时间 。
- Chronos (Zero-shot):总耗时 = 0 训练时间 + 推理时间。
因此,Chronos 提供了一种“仅推理”(Inference-only)的替代方案,这可以极大地简化预测流程,因为你不需要为每一个新出现的预测任务都去重新训练和调整模型 。
🎓 总结时刻
让我们快速回顾一下 Chronos 是如何颠覆时间序列预测的:
- 核心机制 (Tokenization):它不把时间序列当数值看,而是通过“均值缩放”和“量化”,把它变成了语言模型能读懂的 Token 。
- 训练数据 (Data):为了喂饱模型,它使用 TSMixup 和 KernelSynth(高斯过程)生成了大量多样化的合成数据 。
- 模型表现 (Performance):它不仅能“裸考”(Zero-shot)击败传统模型,经过微调后更是能达到最先进(SOTA)的水平 。
微信扫描下方的二维码阅读本文
