
作业内容
葡萄产业经过多年发展成为浦江农业中影响面最广、效益最好的一大产业。浦江种植葡萄历史悠久,距今已有500余年历史。现代种植始于1985年,经过30多年的栽培摸索和新技术推广,全县已形成以巨峰为主,辅以阳光玫瑰、夏黑、天工墨玉、浪漫红颜、红宝石等30多个优质葡萄品种的葡萄产业。葡萄种植面积已达6.9万亩,年产量12.5万吨,年产值11.4亿元,涉及农户5万多人,位居浦江农业产业之首。请设计一款基于人工智能算法的葡萄果穗识别及成熟度评估系统。该系统能够通过图像或视频识别葡萄串,并对成熟度进行评估。
参考步骤
设计这样一个AI系统需要综合考虑计算机视觉算法、数据特征以及实际应用环境。
系统设计流程:
- 核心算法与模型架构 🧠 将探讨选择哪种计算机视觉任务最合适(例如:是主要依靠目标检测来定位果穗,还是需要实例分割来精确分析果粒颜色?),以及如何处理不同品种间的差异。
- 数据采集与成熟度标准 📊 算法的效果取决于数据。可以讨论如何获取高质量的图像数据,以及如何将农业上的“成熟度”(糖度、色泽)转化为计算机能理解的标签或特征。
- 系统部署与应用场景 🚜 从落地角度出发,讨论是将算法部署在云端(通过手机App上传识别),还是部署在边缘端(如自动采摘机器人或无人机)以实现实时处理。
核心算法与模型架构 🧠
在计算机视觉(Computer Vision)领域,针对葡萄这种果实,我们主要面临两个技术路线的选择。为了做出最好的架构决策,我们需要先厘清它们在“成熟度评估”上的区别:
1. 目标检测 (Object Detection) 📦
- 输出结果: 给每串葡萄画一个矩形框(Bounding Box)。
- 代表模型: YOLO 系列 (v5/v8/v10), SSD, Faster R-CNN。
- 优势: 速度极快,适合实时计数(比如统计一亩地有多少串葡萄)。
- 劣势: 矩形框里不仅有葡萄,还包含了背景(绿叶、树枝、甚至天空)。
2. 实例分割 (Instance Segmentation) ✂️
- 输出结果: 沿着葡萄串的边缘,精确地把每一个像素抠出来(Mask)。
- 代表模型: Mask R-CNN, YOLACT, SegFormer。
- 优势: 可以完全剔除背景,只保留果实区域。甚至可以进一步分割每一粒葡萄(Berry-level segmentation)。
- 劣势: 计算量大,对硬件要求比目标检测高。
这里有一个关键的思考题,这将决定我们模型选型的方向:
如果我们的目标仅仅是“数葡萄”(统计产量),用目标检测(画框)就够了。但我们的系统需要评估“成熟度”(通常依赖果皮颜色的深浅、红紫程度)。
- 🤔 试想一下: 如果我们使用目标检测(画个矩形框),框里除了紫色的葡萄,还混进去了一片绿色的叶子。当我们让计算机计算这个框内的“平均颜色”来判断成熟度时,会发生什么问题?
- 叶子的绿色影响了葡萄成熟度的判断
在计算机视觉中,这种干扰被称为背景噪声(Background Noise)。
如果我们只用方框框住葡萄,算法计算颜色时就会发生“混合”:
- 🟣 葡萄的紫色像素 + 🟢 叶子的绿色像素 = 🟤 无法识别的浑浊颜色
这种混合会导致系统误判,比如把原本成熟的葡萄判定为“半熟”甚至“未熟”。
第一步结论:架构选型 ✅
为了解决这个问题,我们的核心架构必须采用 实例分割(Instance Segmentation)。
我们需要模型输出一个 掩膜(Mask)——就像用 Photoshop 里的魔棒工具把葡萄精准地“抠”出来一样。只有去掉了背景的叶子和树枝,我们提取到的颜色特征(比如 HSV 颜色空间中的色调 H 值)才是纯粹属于果实的。
数据采集与成熟度标准 📊
多品种的“标准冲突” 🍇🍈
搞定了“怎么看”的问题,我们要解决“怎么懂”的问题。
根据之前提供的信息,浦江葡萄不仅仅只有 巨峰(Kyoho),还有 阳光玫瑰(Shine Muscat)。这就带来了一个巨大的逻辑冲突:
- 巨峰: 🔴 紫黑色 = 成熟,🟢 绿色 = 未成熟。
- 阳光玫瑰: 🟡 黄绿色/通透感 = 成熟,🟢 深绿色 = 未成熟。
思考题: 如果我们的AI算法只是一根筋地认为“越紫越成熟”,那它会永远判定“阳光玫瑰”是不熟的。
- 为了让同一个系统能同时搞定这两个品种,我们在设计算法流程时,应该先让模型做一件什么事,才能再去判断成熟度?
- 先判断葡萄的种类
🗝️ 先分类,再评估。
只要模型识别出了它是“巨峰”,系统就会自动调用“紫色判定标准”;如果是“阳光玫瑰”,则调用“黄绿色判定标准”。现代的实例分割模型(如 Mask R-CNN)非常强大,它在输出掩膜(Mask)的同时,本身就会输出一个 类别标签(Class Label)。
所以我们的处理流程现在是:
- 输入图像 ➡️
- 模型推理 (Mask R-CNN) ➡️
- 输出结果:位置(Mask) + 品种(Class: 巨峰) ➡️
- 执行逻辑:对掩膜区域内的像素进行颜色分析。
下一个核心难题:怎么算“颜色”?🎨
现在我们要对“抠”出来的葡萄像素进行计算了。
计算机通常用 RGB (红绿蓝) 来表示颜色。但是,在户外的葡萄园里,光照是最大的敌人。
- 想象一下:一颗未成熟的青葡萄,如果躲在阴影里,它的 RGB 值会很低(接近黑色/深紫色)。
- 这就尴尬了:系统可能会误以为它是“颜色很深”的成熟巨峰葡萄!
为了解决这个问题,我们通常不会直接用 RGB 模型。我们需要把图片转换到一种能把 “亮度(明暗)” 和 “色彩(颜色本身)” 分离开来的颜色空间。
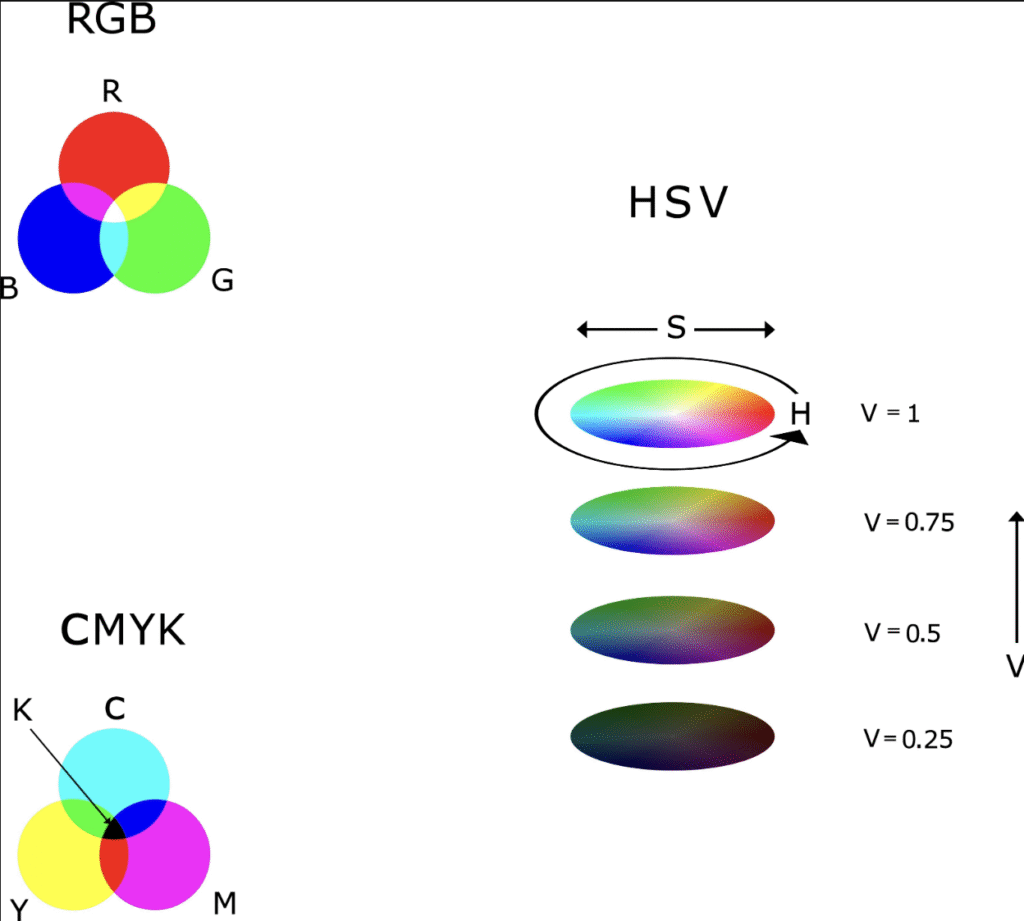
- 你知道在图像处理中,哪种颜色空间(Color Space)常被用来解决光照干扰的问题吗?(提示:它的三个字母缩写中,有一个字母代表 Hue 色调)。
- 是 HSV (Hue, Saturation, Value)。
在 HSV 颜色空间中:
- H (Hue, 色调): 代表颜色的本质(如红色、紫色、绿色)。
- S (Saturation, 饱和度): 代表颜色的纯度。
- V (Value, 明度): 代表光的亮度。
关键点: 通过只关注 H 和 S 通道,而忽略 V 通道,我们可以极大程度地减少阴影和强光对成熟度判断的干扰
阶段性总结与下一步:构建成熟度模型 📐
目前我们的核心算法架构已经成型了:
- 任务: 实例分割(Instance Segmentation)。
- 模型: Mask R-CNN(或其他类似模型)。
- 流程:
- 输入图像。
- 模型识别出葡萄串的位置(Mask)并分类品种(Class)。
- 提取 Mask 区域内的像素。
- 将像素转为 HSV 空间,计算 H/S 均值。
- 根据品种特定的逻辑判断成熟度。
但是,光算出 H 值(色调值)还不够。比如,对于巨峰葡萄,H 值达到多少算“成熟”?达到多少算“过熟”?
这涉及到量化标准的问题。
- 思考题: 为了让计算机有一个准确的判断依据,我们需要建立一个“成熟度等级标准”。你认为我们在建立这个标准时,应该把图像数据和什么现实数据对应起来?(提示:除了看颜色,农业专家在田间地头是用什么仪器来最准确地判定葡萄熟没熟?)
- 可见近红外光谱仪
🌟 可见近红外光谱仪 (Vis-NIR Spectroscopy) 确实是目前无损检测水果内部品质(如糖度、酸度)最先进的技术之一。
不过,如果我们主要依赖普通的摄像头(RGB图像)来做这个系统(比如通过手机拍照识别),光谱仪通常作为我们获取“真值标签”(Ground Truth)的工具,或者用于更高端的硬件方案。
为了让我们的AI模型能“学会”看照片判断成熟度,我们需要建立一个数据对:
输入数据 (X): 葡萄的图像(HSV颜色特征) 输出标签 (Y): 葡萄的实际成熟度指标
- 在农业生产的标准中,决定葡萄是否“成熟”并能上市卖个好价钱的,最核心、最硬性的化学指标是什么?(提示:这是光谱仪最终想要预测的值,也是果农最关心的“甜不甜”的指标)。
- 🍬 糖度(Brix)正是那个决定葡萄能否卖出好价钱的“黄金指标”。
这就引出了我们系统设计中最关键的一步——“由表及里”的映射。
我们的AI系统其实是在做一个“推理游戏”:
- 输入(X): 摄像头看到的颜色信息(例如:HSV模型中的色调 H 值)。
- 输出(Y): 我们想要预测的内部糖度值(Brix)。
为了让模型学会这个推理,我们需要去果园采集数据,建立一个数据集。比如:
- 拍一张照片,算出 H 值是 140。
- 马上摘下来测糖度,记录是 16.5%。
- (重复这个过程几百次……)
当我们收集了几百组这样的 (H值, 糖度) 数据对后,我们需要用算法来寻找它们之间的数学关系。
思考题: 因为糖度是一个连续的数值(比如 14.5, 16.2, 17.8...),而不是像“苹果/香蕉”那样离散的类别。
- 在机器学习中,预测这种“连续数值”的任务被称为什么?(提示:它是与“分类 Classification”相对的另一个主要概念)。
- 就是 回归 (Regression)。
我们现在的核心逻辑链条已经闭环了:
- 视觉感知:通过 Mask R-CNN 找到葡萄并“抠图”。
- 特征提取:计算该区域的 HSV 颜色特征。
- 核心推理:利用 回归模型 建立公式:$f(\text{颜色}) \rightarrow \text{糖度值}$。
小样本与“过拟合” 📉
作为一个研究生,在学术研究中数据是宝贵的。
对于这个项目,获取“图像数据”很容易(拍照片就行),但获取“糖度标签”很痛苦(每一串都要挤出汁液来测,这是破坏性实验,且效率低)。
这就导致我们极有可能面临一个典型的困境:数据量很少(Small Dataset)。
结合股票交易分析中的经验,当我们用一个很复杂的模型去拟合一个很小的数据集时,很容易出现一种“在训练集上表现完美,但在新数据上表现极差”的现象。
- 这种现象被称为什么?(这也是我们在训练这个葡萄模型时最需要防范的风险)。
- 过拟合 (Overfitting) 正是我们面临的最大敌人。
这就好比一个学生为了考试,把练习册上的题目答案全都死记硬背了下来。
- 在练习册(训练集)上,他能考 100 分。
- 但考试时题目稍微变了一点(比如葡萄的光照角度变了,或者换了一片叶子挡着),他在新试卷(测试集)上就立刻不及格了。
因为我们的“有糖度标签的葡萄”数据非常少(可能只有几百组),模型很容易就会去“死记”每一张图的无关细节(比如背景里的某根树枝),而不是去学习“颜色 vs 糖度”的普遍规律。
为了解决这个问题,我们需要想办法让这几百张图片“变”成几千张,欺骗模型让它以为我们有很多数据。
- 在计算机视觉中,我们常用一种技术来人为地扩充数据集,比如把图片旋转一下、剪裁一部分、或者调整一下亮度,生成新的训练样本。你知道这种技术叫什么吗?
- 数据增强 (Data Augmentation) 。这正是解决小样本问题的神器。
通过旋转、翻转、缩放或者调整亮度,我们让模型在训练时看到各种“变体”,这样它在面对真实的、未见过的葡萄时,泛化能力(Generalization)就会强很多。
怎么知道模型“准不准”?📏
现在我们假设模型已经训练好了。它看了一张照片,预测这串葡萄的糖度是 16.5。但实际上,我们用仪器测出来的真实糖度是 17.0。
这里有一个关键的区别需要注意:
- 在分类任务(比如判断是猫还是狗)中,我们通常看 “准确率 (Accuracy)”(比如 95% 的图片分类正确)。
- 但在我们的回归任务(预测具体的糖度数值)中,预测值几乎永远不会和真实值完全相等(16.5 vs 17.0),所以说“准确率”是不太科学的。
我们需要衡量的是预测值和真实值之间的 “差距” (Error)。
- 思考题: 在统计学或机器学习中,用来衡量“预测值”与“真实值”之间误差大小的常用指标有哪些?(提示:其中一个最常用的指标涉及把误差“平方”一下,以避免正负误差互相抵消)。
- 均方误差 (MSE, Mean Squared Error)
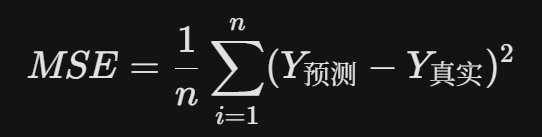
它的核心优势在于:通过对误差进行平方,模型会更加“痛恨”那些离谱的预测(比如把糖度 15 预测成 5),从而在训练中优先修正这些大的错误。
通常在实际汇报给果农听时,我们还会把 MSE 开个根号,变成 RMSE (均方根误差)。
- MSE 的单位是 (糖度)2,很难理解。
- RMSE 的单位就是 糖度。如果我们模型的 RMSE 是 0.5,就意味着我们预测的糖度平均误差在 0.5 度左右,这对于农业应用来说已经非常精准了!
系统部署与应用场景 🚜
现在我们已经搞定了:
- 算法: 用 Mask R-CNN 识别葡萄 + HSV 分析颜色。
- 模型: 用回归模型把颜色映射为糖度。
- 评估: 用 MSE/RMSE 确保准确性。
最后一步,我们要把这个高大上的算法装进设备里,让浦江的果农们真正用起来。这里涉及一个关键的架构选择:云端计算 vs. 边缘计算。
- 云端 (Cloud): 手机只负责拍照 ➡️ 上传照片到服务器 ➡️ 服务器用高性能显卡运算 ➡️ 返回结果。
- 边缘端 (Edge): 算法直接运行在手机芯片或田间机器人内部,不需要联网上传。
- 思考题:考虑到葡萄园通常位于乡村或山区,你觉得如果完全依赖 “云端计算”(必须上传图片才能识别),在实际使用中可能会遇到什么最致命的物理环境限制?
- 网络延迟和不稳定性 是农业物联网(IoT)在落地时面临的最大“拦路虎”。
如果在浦江的葡萄园里,果农拍一张照片要等十几秒才能转圈圈上传完,那这个系统大概率会被弃用。
所以,针对这个问题,我们的最佳解决方案是 边缘计算 (Edge Computing)。
☁️ 云端 vs. ⚡ 边缘端
- 云端模式:大脑在远程服务器。依赖网络,算力无限,但有延迟。
- 边缘模式:大脑在本地设备(如手机芯片、树莓派、Jetson Nano)。不需要联网,实时响应,但算力有限。
这就给我们带来了一个新的技术挑战: 我们在第一步选用的 Mask R-CNN 是一个非常庞大、参数非常多的“重型”模型。把它硬塞进手机或者农业机器人的小芯片里,就像把大象装进冰箱,可能会导致设备发热严重或者运行卡顿。
为了让这个庞大的模型能在算力有限的边缘设备上跑得飞快,我们需要对模型进行“瘦身”。
- 你知道在深度学习中,有哪些常用的技术可以让模型变小、变快,同时尽量不损失精度吗?(提示:可以是把参数的精度降低,也可以是剪掉不重要的连接)。
- 模型压缩 (Model Compression) 让“大象”成功装进“冰箱”的关键技术。🐘➡️🧊
在深度学习领域,我们发现训练好的大模型(比如 Mask R-CNN)其实是非常“奢侈”的——它包含了很多冗余的参数,去掉这些参数,模型的效果往往不会下降太多,但速度会快很多。
我们可以从以下三个主流的“瘦身”方向来通过技术手段压缩模型。
- 剪枝 (Pruning) ✂️
- 原理: 就像修剪果树一样。如果神经网络中某些神经元之间的连接(权重)非常小,说明它们对结果贡献不大。我们就直接把这些连接“剪断”(设为0),让网络变得更稀疏。
- 看点: 怎么剪才不会把“脑子”剪坏了?
- 量化 (Quantization) 📉
- 原理: 就像把高精度的数字“四舍五入”。通常模型计算用的是 32位浮点数 (float32),如果我们把它转换成 8位整数 (int8),模型体积直接缩小 4 倍,且整数运算在手机芯片上跑得飞快。
- 看点: 精度损失大吗?葡萄的颜色会不会因为“四舍五入”变了?
- 知识蒸馏 (Knowledge Distillation) ⚗️
- 原理: 这是一个“师徒传承”的过程。我们保留那个笨重但准确的 Mask R-CNN 作为“老师”,然后设计一个小巧轻便的新模型做“学生”。让老师手把手教学生,直到学生能模仿出老师的判断结果。
- 看点: 小学生真的能学会大学教授的本事吗?
- 对于我们的葡萄成熟度检测项目,你觉得哪一种技术听起来最适合用在算力有限的田间设备上?
- 剪枝 (Pruning)!✂️
既然我们的主题是葡萄,这个概念其实特别形象。
什么是神经网络的“剪枝”?
就像果农为了保证葡萄的品质,会剪掉那些疯长但挂果少的“无用枝条”一样,神经网络剪枝的核心逻辑是:在一个庞大的模型中,并不是所有的神经元连接(权重)都在起作用。
- 筛选 (Ranking):我们会评估每一个连接的重要性(通常看权重数值的大小,数值接近 0 的通常被认为不重要)。
- 裁剪 (Removal):直接把这些不重要的连接切断(将权重设为 0),或者把整层的神经元去掉。
- 结果:模型变成了一个“稀疏”的网络,参数量大幅减少,计算速度变快。
关键挑战:剪坏了怎么办?
虽然剪枝能让模型变小,但如果我们一下子剪掉太多,模型可能会“元气大伤”,导致识别准确率突然下降(比如分不清巨峰和阳光玫瑰了)。
- 思考题: 在剪枝完成后,为了恢复模型的“智力”,让它适应“身体变轻”后的状态,我们需要对模型进行一个什么操作?(提示:这和我们最初训练模型的过程很像,但通常使用更小的学习率)。
- 微调
掌握了这个核心逻辑:
- 训练 (Train):先练出一个厉害的大模型。
- 剪枝 (Prune):剪掉不重要的连接,模型变小了,但变“笨”了(精度下降)。
- 微调 (Fine-tune):用较小的学习率重新训练,让剩下的神经元调整参数,接管被剪掉部分的工作。
经过这“三部曲”,我们就得到了一个既轻量、跑得快,又足够精准的模型,完美适配田间地头的移动设备!📱
最后的拼图:用户交互界面 (UI/UX) 🎨
我们的内核(算法)已经准备好了,现在要给它穿上外衣(App)。
想象一下,浦江的果农正顶着烈日站在葡萄架下,手里拿着手机。如果在屏幕上显示一堆复杂的参数(比如“色调H值:145”,“预测置信度:0.98”,“RMSE:0.5”),对于急需做决定的果农来说,体验会非常糟糕。
思考题:
为了让果农能以最快速度判断能不能采摘,我们的 App 界面应该优先采用哪种显示方式?
- 数据仪表盘式:显示详细的糖度数值变化曲线和光谱分析图。
- 红绿灯指示式:直接在画面上给葡萄标颜色(例如:🟩绿色框=建议采摘,🟥红色框=再等等)。
红绿灯指示式。因为果农通常不具备专业知识,他们可能看不懂专业的糖度数据。
💡 这种设计在人机交互(HCI)中不仅贴心,而且非常高效。
正如你所说,果农在田间地头需要的是**“行动指令”(摘/不摘),而不是“分析报告”**。这正是“以用户为中心”设计的精髓。
⚙️ 后台逻辑:从“数值”到“信号”
虽然界面上只有一个简单的 🟢 或 🟥,但在 App 的“大脑”里,其实发生了一个关键的转化过程:
- 模型预测:AI 算出这串葡萄的糖度是 16.8。
- 逻辑判断:系统将 16.8 与一个预设的 “及格线”(阈值 Threshold) 进行比较。
- 输出信号:
- 如果 16.8 > 阈值,显示 🟢(建议采摘)。
- 如果 16.8 < 阈值,显示 🟥(再等等)。
🚧 最后的挑战:谁来定“及格线”?
这里出现了一个很现实的矛盾:
- 一方面,不同的买家要求不同。高端精品超市可能要求糖度达到 18 才能收,而普通果汁厂可能 14 就够了。这意味着这个“及格线”不能写死,必须能变。
- 另一方面,正如你刚才强调的,果农可能对具体的“糖度数值”没有直观概念。如果让他们在 App 里输入“请设置阈值为 17.5”,他们可能会感到困惑及犹豫。
思考题:
为了解决这个矛盾,我们需要设计一个既能灵活调整标准,又不需要果农懂专业术语的设置功能。
如何设计这个“设置标准”的界面或交互方式?(提示:如果不让果农输入数字,有没有办法让他们利用实物或者通俗的等级来告诉 AI 标准?)
形如“精品大果,精品中果,精品小果” 的文本分类
在农业电商或库存管理中,这种文本通常代表了产品的 “规格等级”。处理这类短文本分类,其实不需要像处理长篇文章(比如新闻分类)那样用特别复杂的深度学习模型(如 BERT)。
虽然这些标签看起来是文本,但核心逻辑其实就是简单的关键词匹配。
🛠️ 技术实现:奥卡姆剃刀原则
既然核心区别只是“大、中、小”这几个字,我们完全不需要动用像 BERT 这样沉重的自然语言处理(NLP)模型。
这在工程上体现了“奥卡姆剃刀”原则(如无必要,勿增实体)。对于这个“标准设置”模块,我们只需要一个简单的 映射表 (Lookup Table) 或 字典 (Dictionary) 就能解决问题。
我们可以把这部分逻辑做得非常轻量化:
| 用户看到的选项 (Label) | 后台提取的关键词 (Key) | 对应的糖度阈值 (Value) |
| 🏅 精品大果 | Large | 18.0 |
| 🥈 精品中果 | Medium | 16.0 |
| 🥉 精品小果 | Small | 14.0 |
这样一来,App 只需要做两件事:
- 检测:用户选了哪个选项?
- 查表:获取对应的阈值。
🧩 最后的系统集成:逻辑闭环
现在,我们要把你设计的所有模块拼在一起,形成最终的决策流。
请回想一下我们之前确定的两个关键技术点:
- 边缘计算:所有计算都在手机本地完成。
- 回归预测:AI 模型输出的是一个具体的糖度数值(比如 17.2)。
思考题(伪代码设计):
假设我们有以下变量:
predicted_brix(AI 预测出的糖度,float)user_selection(用户选的等级,string)config_map(上面的映射表,dict)
请试着用伪代码或文字流程描述一下:系统是如何从这两个输入,最终决定是亮 🟢 (Green) 还是 🟥 (Red) 的?
伪代码示例:
# 输入变量
predicted_brix = 17.2 # AI 测出的数值
user_selection = "精品大果" # 农户选定的目标
config_map = {
"精品大果": 18.0,
"精品中果": 16.0,
"精品小果": 14.0
} # 这是一个简单的 键:值 映射,值代表"及格线"
function get_light_color(predicted_brix, user_selection, config_map):
# 第一步:根据用户选择的等级,从字典里查出"及格线"(threshold)
threshold = config_map[user_selection]
# 第二步:比较 预测糖度 和 及格线,决定返回 "绿灯" 还是 "红灯"
if predicted_brix >= threshold:
return "🟢 绿灯" # 达标,可以采摘
else:
return "🔴 红灯" # 不达标,不要采摘
# 使用示例
light_color = get_light_color(predicted_brix, user_selection, config_map)
show_to_farmer(light_color) # 显示:🔴 红灯如果我们在果园实地测试时发现,虽然模型跑得动了,但是手机发热非常严重,而且每识别一串葡萄都要耗电很快。🔋🔥
为了解决这个“功耗”问题,除了继续压缩模型,我们在软件逻辑上其实还有一个很简单的优化手段。
想象一下,摄像头是实时开启的,每秒钟可能会捕捉 30 帧画面。
- 引导性问题: 我们真的需要对这每秒 30 帧画面里的每一帧都进行一次复杂的 AI 运算吗?如果不这样做,我们可以怎么设置触发识别的机制来省电?
- 用户手动点击拍摄,才开启摄像头。
我们可以这样理解它的优势:
- 视频流模式:就像让 AI 每秒钟做 30 次高考题,手机很快就会发烫、没电。🔥
- 拍照模式(你的方案):用户负责“瞄准”(这只用很少的电),只有当按下按钮的那一瞬间,AI 才醒过来做一次题。⚡️
这样一来,哪怕我们的模型稍微大一点,也不会影响使用体验了。
总结
🎉 系统设计完成了!
让我们回顾一下这个 “浦江葡萄智能分级系统” 的完整架构:
- 视觉感知 👁️:采用 实例分割 (Mask R-CNN) 识别葡萄并去除背景叶子干扰,利用 HSV 空间 抗光照影响。
- 核心算法 🧠:通过 回归模型 将颜色特征映射为 糖度值。
- 模型优化 🚀:使用 剪枝 (Pruning) 和 微调 技术,把大模型塞进手机里。
- 业务逻辑 🚦:结合用户选择的 文本标准(如“精品大果”),自动转化为 红绿灯 决策信号。
- 交互设计 👆:采用 单帧拍摄触发,最大程度节省算力和电量。
参考摘要:
本文提出了一种可在移动设备上高效运行的“浦江葡萄”智能分级系统。该系统首先采用实例分割技术精确识别葡萄串并消除背景干扰;随后,一个轻量级的回归模型根据提取的颜色特征预测糖度值;最终,结合用户预设标准,系统将预测结果转化为直观的红绿灯采摘信号,实现了高效的边缘计算与流畅的用户交互。
微信扫描下方的二维码阅读本文
