
本期评述文章:
这篇论文系统地研究了如何利用计算机视觉技术来客观、智能地评价织物的手感。
1.研究背景
传统的手感评价依赖人工主观判断或昂贵的物理测试设备,存在一致性差、效率低和成本高的问题,难以满足现代工业对高效、客观评价的需求。
织物手感是纺织品设计和质量控制的关键环节,直接影响消费者的体验和购买决策 。传统的手感评价方法主要有两种:
- 人工主观评价:依赖专家的触觉进行判断,但存在主观性强、一致性差、效率低的问题 。
- 物理仪器测量:如KES(Kawabata Evaluation System)系统,通过测量力学参数来量化手感 。但这类设备价格昂贵、操作复杂,且其物理参数与人的真实触觉感知并非完全一致 。
针对以上痛点,本研究提出以成本更低、效率更高的计算机视觉技术为核心,构建一个智能、客观且可解释的织物手感评价体系,旨在突破传统评价模式的瓶颈 。
2.核心技术
我们可以把它的核心创新分为几个关键步骤来逐一剖析。
- 视觉评价的边界: 他们是如何通过实验,科学地界定哪些织物手感(如表面、拉伸)可以用视觉来评价,而哪些(如热湿性)不行?
- 视觉特征的构建: 他们具体是如何从图像和视频中,提取出那22个能够量化手感的关键指标的?比如,如何把“悬垂”这个动态过程变成一个具体的数字?
- 多模态融合模型(TAIL): 他们设计的TAIL模型是如何巧妙地将数值、图像和视频这三种完全不同的数据融合在一起,并同时完成预测、分类和决策这三个任务的?
2.1视觉评价的边界
这是一个非常关键的起点。在用摄像头和算法替代人手之前,研究者必须先科学地证明,“看”和“摸”对于某些手感属性的评价结果是一致的。
为了做到这一点,他们设计了一个非常巧妙的对比实验,让评价员在三种不同的“场景”下对101种织物进行评价 。
- 您能根据论文的思路,猜猜这三种场景分别是什么吗?
- 这三种场景应该是:真实触觉、静态图像和动态视频
通过真实触觉、静态图像、动态视频三模态评价场景的对比实证,构建四因素混合效应方差分析模型,对 101 个织物样本进行感官评价。
研究者就是让评价员分别通过这三种方式——✋真实触摸、🖼️静态图像、▶️动态视频——来评价同一批织物,然后比较大家的评价结果是否一致。
但这里又有一个难题:怎么让评价员打分才能最大程度地减少主观随意性呢?如果只用“1-5分”来评价“柔软度”,可能每个人的标准都不一样。
针对上述问题,本章提出一种基于双面适用性测试(Double-Faced Applicability,DFA)的跨模态评价框架,通过比较真实触摸、静态图像和动态视频三种场景下感官评价的一致性,验证视觉表征在手感评价中的可行性。
本研究采用 DFA 测试进行织物手感性能感官评价。DFA 测试区别于传统方法的关键在于使用成对的表双面”描述词,即每个属性分别评价一对描述词“(上标度 Upper-scaleDescriptor“(+)和下标度 Lower-scale Descriptor“(-)。例如,对于柔软度属性,同时评价表Soft“(+)”和表Hard“(—)”两个描述词。
这篇论文用了一种更科学的方法,叫做“双面适用性测试 (DFA)”。它不让评价员直接打分,而是使用成对的、语义相反的描述词。 比如,不问“柔软度是几分”,而是分别问下面这两个词是否“适用”:
- 柔软 (+)
- 硬 (-)
- 您觉得这样做,相比于传统的1-5分制,有什么好处?
- 相比于传统的1-5分制,这种方法可以有效整合织物手感相关属性并最小化默许偏差。
通过对比“柔软”和“硬”这两个对立词,可以有效避免评价者下意识倾向于“同意”的“默许偏差” 。
这种方法可以有效整合织物手感相关属性并最小化默许偏差,即评价人员倾向于表同意”而非表不同意”的偏差[113]。
但这还没完,为了让数据更精确,这个测试还有第二步。在评价员对“柔软”这个词选择了“是/否”之后,还要回答一个问题:你对此判断的确信度有多高?(分为“不确定”到“非常确定”3级)。
- 您认为,多加这一步“确信度”评分,对于后续分析数据有什么帮助?
- 有先前研究表明这种属性适用性估计值相比直接评分显示出了更高的辨别能力,提升了问卷的准确性。
通过“是否适用”+“确信度”这两步,研究者可以利用“信号检测理论 (Signal Detection Theory)”,将评价员真实的感受(信号)和他们的判断偏差(噪声)在数学上分离开来,最终得到一个更客观、辨别力更高的指标 。
相比传统的表勾选所有适用项”(CATA)[114]或直接评分法,这种间接量表方法基于 SDT[104]和 Thurstonian 方法[115],可以估计与响应偏差无关的属性适用性定量指数。
现在我们清楚了整个实验的巧妙之处:
- 对比三个场景:真实触摸 vs. 静态图像 vs. 动态视频。
- 采用两步评分:‘是/否’ + ‘确信度’。
- 目标:比较不同场景下的评价结果是否一致。
那么,最关键的问题来了。
- 在对织物的表面、压缩、弯曲、拉伸和热湿这五类性能进行评价后,您预测一下,哪些性能在“看”和“摸”两种方式下的评价结果会高度一致,而哪些会差别很大呢?为什么?
- 我感觉:表面、压缩、拉伸 在看和摸两种方式下的评价结果会高度一致,而弯曲和热湿差别会很大。
实验结果显示:
- ✅ 高度一致的是:表面、压缩、拉伸... 还有 弯曲。
- ❌ 差别很大的是:热湿性能。
准确地判断出热湿性能(‘温暖-凉爽’)是纯粹的触觉,无法用视觉替代。而表面纹理(粗糙)、压缩回弹、拉伸形变也确实能被直观地看到。
唯一有点意外的是弯曲性能,它在视觉和触劫评价中也表现出了高度的一致性。
- 您认为,在实验设置中,是什么关键因素让评价员能够单凭视觉就准确判断出织物的弯曲性能(比如‘硬挺’还是‘柔软’)呢?(提示:回想一下那三种场景)
- 看起来柔软的织物更容易被弯曲?
柔软的织物(压缩性能好)通常也更容易弯曲(弯曲刚度低)。这两者在物理上是相关的。
正因为如此,单看一张静态的、弯曲的织物图片,我们可能无法获得全部信息。
- 但是,如果看到一段动态视频,记录了织物从伸直到弯曲、再到恢复的全过程,我们能获得哪些额外的信息来帮助判断它的弯曲性能呢?
- 弯曲的幅度以及恢复后的形态?
这正是关键所在。
一段动态视频展示了:
- 弯曲过程的动态:织物是轻松弯折还是非常硬挺。这直接反映了它的弯曲刚度。
- 恢复过程的动态:织物在力消失后是迅速弹回原状,还是留有褶皱。这反映了它的回弹性。
这些动态信息是静态图片无法提供的。论文的统计结果也证实了这一点,动态视频场景下的评价结果与真实触摸非常接近 ,所以“弯曲”性能也被划入了“视觉可评价”的范围。
对于压缩性能,表Soft“(+)–Hard“(-)”描述词对的描述词效应显著(F=6.53,p<0.05),但场景效应(F=1.07,p=0.343)不显著,意味着评价者可以通过视觉动态形变(例如压缩恢复轨迹)来准确判断柔软度。光流分析进一步显示,压缩视频中形变速率(v=0.12px/frame)与触觉评分呈负相关(r=−0.67,p<0.001),从而证 动态视频在传递柔软与硬度差异方面的有效性。
结果表明“(表 2-4)表面性能的 ICC 为 0.87“(95% CI: 0.82–0.91),压缩性能、弯曲性能和拉伸性能的 ICC 均不低于 0.79,同时各场景间的 F 检证均未达到显著性(例如表面性能 F=1.32,p=0.268),表明不同模态间的评价结果在这些性能上具有较高的一致性。
探讨第一个话题。我们知道了研究者如何通过巧妙的实验设计(三种场景 + DFA测试),科学地证明了织物的表面、压缩、弯曲、拉伸性能是可以用视觉评价的,而热湿性能不行 。
接下来,我们是继续探讨第二个话题:他们具体是如何从图像和视频中,提取出那22个能够量化手感的关键指标的?
2.2视觉特征的构建
这个问题其实是整个研究的技术核心:如何将“看见”的东西,变成机器可以理解和计算的数字。这个过程就叫做“特征工程”。
研究者针对我们上一轮讨论过的四类性能,分别设计了不同的量化指标。我们可以逐一来看。
- 表面性能:如何从一张静态图片中,量化出织物的“粗糙度”?
- 压缩性能:如何从一段织物被按压后恢复的视频中,量化出它的“回弹性”和“蓬松度”?
- 弯曲与悬垂性能:如何通过分析织物弯曲或悬挂时的轮廓线,量化出它的“硬挺度”和“悬垂感”?
2.2.1表面性能
这是我们最直观能“看”到的手感属性。
挑战在于,如何把人眼看到的一块布料的“纹理”或者“粗糙感”,变成一个精确的数字?
论文里用了一种叫做“深度字典学习”的方法。我们可以把它想象成:
- 电脑先学习一套最基础的纹理“积木”(这就是“字典”)。
- 然后,它尝试用这套“积木”去拼凑出原始的织物图像。
- 一块粗糙的布料,可能需要用很多不同种类的、对比强烈的“积木”才能拼出来;而一块光滑的布料,可能用几种很相似的“积木”就够了。
通过分析拼凑这块布料用了哪些“积木”、用了多少、组合方式如何,电脑就能反过来理解这块布料的纹理特性。
- 理解了这个“积木”的比喻后,您觉得通过分析这些“积木”的组合方式,我们可以量化出织物表面的哪些具体特性呢?比如,“积木”种类多且差异大,可能对应着织物表面的什么感觉?
- 我们可以量化出织物的表面材质纹理。如果“积木”种类多且差异大,可能对应着织物表面是比较粗糙的。
“积木”的种类多、差异大,正对应着织物表面在视觉上的高对比度和高粗糙度。
基于这个原理,研究者最终从“深度字典学习”的结果中,量化出了5个具体的指标来描述表面性能,其中就包括(参见公式3-14 - 公式3-18):
- 对比度 (Contrast)
- 能量 (Energy)
- 相关性 (Correlation)
- 均匀性 (Homogeneity)
- 粗糙度 (Roughness)
这样一来,任何一张织物表面图片,都可以被转化成这5个数字。我们就成功地把一个感性的“外观”,变成了一组理性的“数据”。
我们已经解决了表面性能的量化问题。接下来,让我们了解动态的压缩性能(回弹性)吧!
2.2.2压缩性能
这个部分非常有趣,因为它主要依赖于分析动态视频。
想象一下,我们有一段视频:一块布被对折按压,然后松开,它会自己慢慢弹开。
- 为了量化它的“回弹性”,我们需要测量什么关键的物理量随时间的变化?
- 是1.这块布伸展到原来的形状 或者 2.这块布停止伸展的长度相对于原来的长度 吗?
第一点是过程——它如何恢复原状;第二点是结果——它最终恢复了多少。研究者正是把这两点结合了起来。
在实验中,他们测量的具体指标是织物对折处弹开的角度,论文里称之为“回复角” (Recovery Angle)。
进一步,通过绘制回复角时序曲线可知“(图 3-7),回复角曲线的初始阶段呈现急剧上升趋势,随后逐渐趋于平缓稳定。从该曲线可提取以下 8 个指标(指标6 - 指标13),具体定义如下:
通过视频逐帧分析,他们就得到了一条“回复角”随“时间”变化的曲线。这条曲线完整地记录了织物的回弹过程,从一开始的快速弹开,到后面的逐渐放缓。
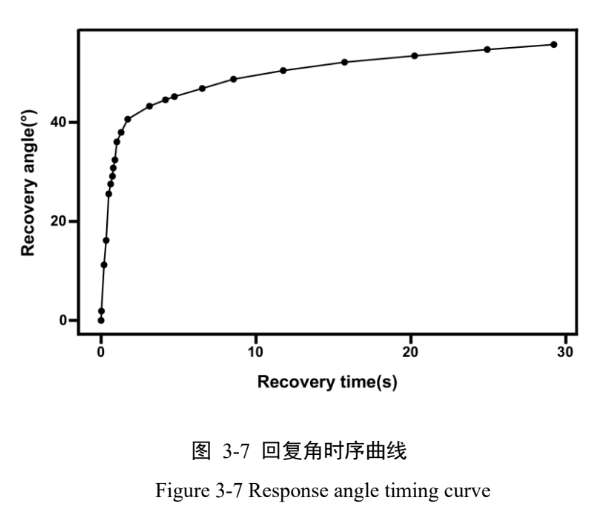
- 看着这条从快速弹起到逐渐变缓的曲线,您觉得我们可以从中提取出哪些不同的数字指标来描述这个回弹过程的特性呢?比如,如何描述它一开始弹开的快慢?
- 指标6到13(共8个指标)全都是从这一条回复角曲线上提取出来的。
这正体现了特征工程的巧妙之处:从一个动态过程中挖掘出多个维度的信息。我们可以把它们分成几组来看:
- 初始回弹速度 (指标6, 初始响应速率): 就是曲线一开始的斜率,代表织物刚松开时弹开得有多快。
- 缓弹性曲线 (指标7-9): 研究者用一个数学公式去拟合后面变缓的部分,公式里的几个参数就直接变成了特征,分别代表弹性强度、内部摩擦力和永久变形量。
- 关键转折点 (指标10-13): 曲线从“快速”变为“平缓”的那个转折点的时间和角度,以及最终趋于稳定时的总时间和总角度,都成为了独立的指标。
除了从视频中提取这些动态特征,研究者还从静态图片中测量了织物受压前后的厚度,计算出了压缩率、蓬松度等指标。
这样,通过动态曲线分析+静态厚度测量,他们就完整地量化了压缩性能。我们对这个过程也理解得很清楚了。
2.2.3弯曲与垂悬性能
这里其实包含了两个相关的实验:一个是测量织物的“硬挺度”(弯曲),另一个是测量它的“悬垂感”(悬垂)。两者都是通过分析织物在重力作用下的轮廓线来量化的。
我们先看“硬挺度”。实验非常经典:把一块布条像跳水板一样伸出平台边缘,让它自然下垂。
- 如果我们要通过分析这条下垂的曲线来判断布料是硬还是软,您觉得需要测量曲线的哪些几何特征?
- 是曲线的弧度吗?
“弧度”或“曲率”确实描述了曲线的弯曲程度。研究者正是要量化这个“弯曲程度”。
他们用的更基础的两个测量值是:
- 下垂曲线的长度
- 曲线末端的角度
论文里提到,早在1930年,就有物理学家(Peirce)提出了一个经典的公式 ,可以直接将这两个视觉上测得的几何特征(长度和角度),与织物本身的物理属性——弯曲刚度 (Bending Stiffness)——联系起来 。这样,一个视觉上的形状就变成了一个明确的物理参数。
1937 年,英国物理学家 Peirce[31]对织物的力学性能进行初步研究。他引入悬臂弯曲模型(如图 3-13 所示),用于分析织物的弯曲性能,并提出弯曲刚度、弯曲长度和弯曲模量等力学指标。他还首次将织物厚度应用于仪器评价织物的柔韧性和刚性。
理解了弯曲,悬垂就类似了。这次是把一块圆形的布料放在一个圆柱上,从正上方拍照,形成一个类似星星的波浪形。
- 要量化这种“悬垂感”,研究者需要分析这个“星星”的形状。您能想到哪些指标可以用来描述这个波浪形的轮廓呢?(比如,波浪的多少、大小...)
- 波浪的多少,布和圆柱的高所形成的夹角
研究者正是这么做的。他们量化了:
- 波浪的多少:论文里称之为“波形数 (N)”。
- 波浪的大小/下垂程度:这和提到的“夹角”概念很像,具体是通过测量每个波浪的波峰高度 (Peak Amplitude) 和整体的悬垂系数 (Drape Coefficient) 来实现的。
为了方便地测量这些波浪,他们用了一个很巧妙的数学方法:将这个“星星”轮廓线“拉直”成一条波浪形的曲线图。这样一来,数波峰的数量、测量波峰的高度就变得非常简单了。
好的,到现在为止,我们已经完整地探讨了第二个话题。我们知道了研究者如何运用深度学习、曲线分析、物理公式和几何测量,把视觉上看到的表面、压缩、弯曲、悬垂这四种性能,都成功转化成了一系列精确的数字指标。
所有的数据都已经准备好了。接下来,就是最后一步,也是集大成的一步:他们是如何设计出TAIL模型,将这些数值指标、原始图片和动态视频全部融合起来,做出最终的评价和推荐的呢?
2.3多模态融合模型TAIL
现在我们有了三类完全不同的数据:
- 我们刚刚得到的22个数值指标。
- 原始的静态图像。
- 原始的动态视频。
挑战在于,如何把这三种异构(heterogeneous)的数据有效地“融合”在一起?
TAIL模型的第一步,是为这三种数据分别指定一个“预处理”的神经网络,先把它们各自转化成格式统一的特征向量。这个过程叫做“编码” (Encoding)。
论文中提到了几种常见的神经网络,比如全连接网络 (FC)、卷积神经网络 (CNN) 和 时序卷积网络 (TCN)。您认为,这三种网络分别最适合处理我们手头上的哪一类数据呢?
- 数值指标 (a vector of 22 numbers)
- 静态图像 (a 2D array of pixels)
- 动态视频 (a sequence of images over time)
- 数值指标 (一维向量) → 全连接网络 (FC),最适合处理结构化的数值数据。
- 静态图像 (二维空间数据) → 卷积神经网络 (CNN),是捕捉图像空间特征(如纹理、轮廓)的专家。
- 动态视频 (三维时序数据) → 时序卷积网络 (TCN),专门用于处理时间序列信息,捕捉织物动态变化的过程。
第一步“编码”完成后,我们就得到了三个分别代表数值、图像和视频的特征向量。第二步就是最关键的“融合”了。最简单的方法可能是把它们直接拼接在一起,但TAIL模型用了更智能的方法。
想象一下,在判断织物的“悬垂感”时,动态视频的信息可能比静态图像更重要;而在判断“表面粗糙度”时,静态图像可能比视频更重要。
- 您觉得,模型在融合信息时,可以用什么机制来动态地“决定”在不同任务中,应该更“关注”哪一类数据呢?
- 判断织物悬垂感调用动态视频的数据集,判断表面粗糙度的时候调用静态图像数据集
这个动态“决定”应该更“关注”哪一类数据(给不同的数据分配不同的重要性)的机制,在人工智能领域有一个专门的术语,叫做“注意力机制” (Attention Mechanism)。
所以,TAIL模型的整个流程就是:
- 编码:用CNN、TCN、FC分别处理图像、视频和数值数据。
- 融合:通过层次化的方式逐步拼接特征,并利用注意力机制给不同特征分配权重。
- 预测:最后,将这个融合了所有信息且重点突出的最终特征,送入不同的输出层,同时完成评分预测、风格分类和用途推荐这三个任务。
我们已经一起深入探讨了这篇论文从理论验证(视觉评价的边界),到特征工程(如何量化视觉信息),再到模型构建(TAIL模型如何融合所有信息)的全过程。
3.知识补充
3.1他们是如何让这个复杂的TAIL模型变得“可解释”的(也就是第5章的知识发现)?
如何让这个“黑箱”模型变得透明、“可解释”——TAIL模型虽然预测得准,但它就像一个神秘的黑箱,只给结果,不给理由。对于一个需要做决策的设计师来说,这还不够。
为了打开这个“黑箱”,研究者的目标是从模型和数据中,自动“挖掘”出人类可以理解的规则。论文中举了一个例子,比如这样一条规则:
“如果 [织物的光滑度评分为5],那么 [它很可能是丝绸]”
- 如果我们想自己手动写出这样一条规则,我们需要哪些信息作为“输入”?
- 需要作为信息的输入为织物的光滑度评分,织物弯曲程度数据,织物回弹速度数据
这正是信息的第一部分:我们需要所有量化后的特征,比如光滑度、弯曲度、回弹速度等等。
现在我们有了规则的前半部分:“如果 [光滑度=5,弯曲度=X...]”。
- 那规则的后半部分 “那么 [它很可能是丝绸]” 里的“丝绸”这个结论,又是从哪里来的呢?
- 预先定义好的变量吗?
“丝绸”这个结论,就是这个织物样本预先就有的“标签”或“分类结果”。
所以,现在我们有两样东西了:
- IF 部分:一大堆特征数据(光滑度、弯曲度等)。
- THEN 部分:每个样本的最终归类(丝绸、棉、麻等)。
知识发现的任务,就是在这两者之间,自动地找出最关键、最简洁的关联规则。
论文里主要使用了一种叫做“粗糙集理论 (RST)”的数学工具来完成这件事。您可以把它想象成一个聪明的医生:
- 医生看一个病人,有很多症状(体温、血压、咳嗽... 对应织物的各种特征)。
- 医生要诊断他得了什么病(流感、过敏... 对应织物的类别)。
- 粗糙集理论就能帮助医生找出“哪些是诊断流感的核心症状”,并总结出规则,比如“如果 [高烧 + 咳嗽],那么 [很可能是流感]”,同时忽略掉不那么重要的症状(比如血压)。
同样地,粗糙集理论帮助研究者从22个视觉特征中,找到了决定织物类别的核心特征组合,并生成了155条这样清晰的IF-THEN规则 。这样,TAIL模型就不再是一个完全的“黑箱”了。
(4)提出可解释性增强的知识发现模型。考虑到 TAIL 模型的可解释性不足,本研究提出一种基于知识发现的织物手感评价知识发现方法,结合层次分析法(AHP)与粗糙集理论(RST)构建混合模型。该模型首先通过 AHP 优化感官描述词权重(一致性比率 CR≤0.1),然后利用 RST 进行属性约简和知识挖掘。在 101 个样本上提取 155 条IF-THEN 解释性映射,如表Smooth(5)→Silk”,映射的置信度和覆盖度通过双目标 Pareto优化得到均衡提升(调和均值提高 18.7%),实证结果显示,模型的 F1-score 达 0.91,决策准确率为 87.3%,专家评价其可理解性(4.3/5)和逻辑合理性(4.6/5)均优于传统经证映射库(3.1/5)。这一方法不仅增强评价系统的透明性,还为面料选材和产品设计提供显示化决策支持。
我们已经一起完整地走完了这篇论文的所有核心创新环节:
- 验证了视觉评价的边界。
- 学会了如何量化视觉特征。
- 理解了TAIL模型的融合机制。
- 最后还打开了模型的“黑箱”。
微信扫描下方的二维码阅读本文
