
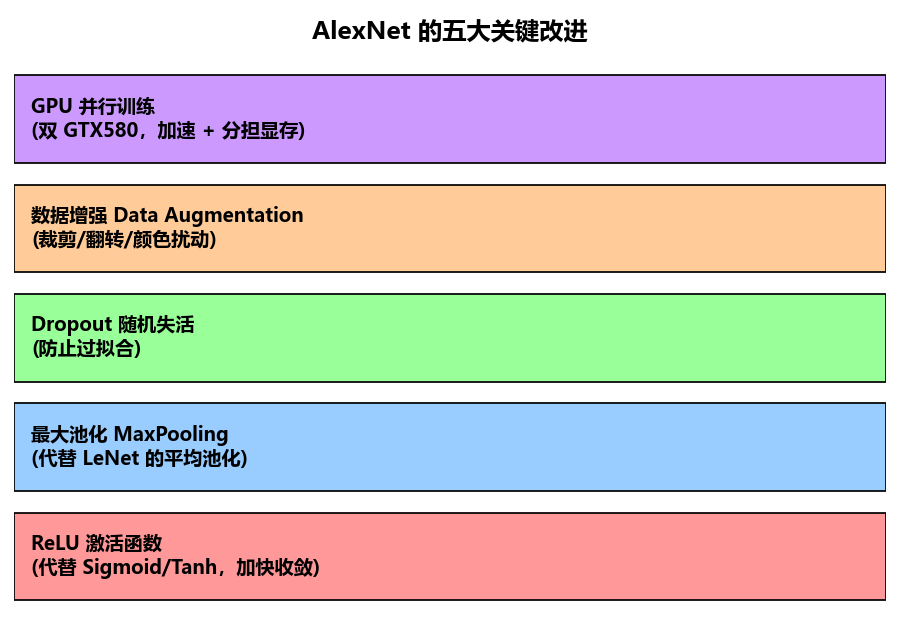
ALEXNET相对于LeNet,做出了五个改进:
- ReLu函数
- 最大池化
- 随机丢弃
- 数据扩增
- GPU并行训练
首先,我们来看看什么是ALEXNET:
1. AlexNet 的基本情况
- 作者:Alex Krizhevsky、Ilya Sutskever(Hinton 的学生们)
- 提出时间:2012 年
- 数据集:ImageNet(120 万张图像,1000 个类别)
- 规模:约 650,000 个神经元、6000 万参数、6500 万连接
2. 网络结构(典型版)
输入是 227×227×3彩色图像,网络包含 8 层可训练的层(5 个卷积层 + 3 个全连接层):
- Conv1:96 个 11×11 卷积核,stride=4 → 输出 55×55×96
- Max Pooling:3×3, stride=2 → 27×27×96
- Conv2:256 个 5×5 卷积核 → 27×27×256
- Max Pooling:3×3, stride=2 → 13×13×256
- Conv3:384 个 3×3 卷积核 → 13×13×384
- Conv4:384 个 3×3卷积核 → 13×13×384
- Conv5:256 个 3×3卷积核 → 13×13×256
- Max Pooling:3×3, stride=2 → 6×6×256
- FC1:全连接层,4096 个神经元
- FC2:全连接层,4096 个神经元
- FC3:全连接层,1000 个神经元(对应 1000 个类别,Softmax 输出)
3. AlexNet 的关键创新
- 使用 ReLU 激活函数(代替传统的 Sigmoid/Tanh,加快收敛速度)。
- 使用 Dropout(随机丢弃神经元,防止过拟合)。
- 数据增强(图像平移、翻转、颜色扰动,扩大训练集有效规模)。
- GPU 并行训练(首次把 GPU 引入大规模卷积神经网络训练,大大提高训练速度)。
- 最大池化(突出最显著的特征,对背景噪声更鲁棒)。
4. 影响
- 在 2012 ILSVRC 比赛中,Top-5 错误率仅 15.3%,而第二名是 26.2%,差距非常大。
- AlexNet 的成功让业界认识到:深度卷积神经网络在大规模数据和 GPU 加速下,能远超传统方法。
- 后续的 VGG、GoogLeNet、ResNet 都是在 AlexNet 的基础上发展起来的。
接下来让我们分别看看每一个创新点
1.ReLu函数
在 AlexNet 里用的 ReLU(Rectified Linear Unit,修正线性单元),是它最重要的创新之一。
1. 传统激活函数的问题
在 AlexNet 之前,常见的非线性激活函数是 Sigmoid 和 tanh:
Sigmoid:
,输出在(0,1) 之间
tanh:
,输出在 (−1,1)之间
这两种函数的主要缺点:
- 计算复杂:涉及指数运算,早期计算资源有限,效率不高。
- 梯度消失:在输入很大或很小时,函数会饱和(趋近于常数),导数接近 0,导致梯度几乎传不下去 → 深层网络难以训练。
2. ReLU 的定义
f(x)=max(0,x)
非常简单:小于 0 的直接变成 0,大于 0 的保持原值。
3. ReLU 的优点
- 计算高效:只需比较和截断,比 sigmoid/tanh 快得多。
- 缓解梯度消失:在 x>0 区域,梯度恒为 1,可以把误差有效传递到深层。
- 稀疏激活:当 x<0 时输出 0,很多神经元不激活,使网络稀疏化,减少参数依赖,提高泛化能力。
- 收敛速度快:在 AlexNet 的实验里,ReLU 网络的收敛速度比 tanh 快 6 倍以上。
4. ReLU 的小问题与变种
- “神经元死亡”:如果某个神经元长期输入为负,就一直输出 0,不再更新。
- 解决办法:出现了 Leaky ReLU、Parametric ReLU、ELU 等变体,在负半轴给一个小斜率,而不是完全为 0。
2.最大池化MaxPooling
1. 什么是池化?
池化就是在 特征图的局部区域 内,按照某种规则把多个像素“聚合”为一个值,从而:
- 缩小特征图尺寸(降采样)
- 减少计算量
- 增强模型对平移和局部变化的鲁棒性
简单理解就是:
把邻近像素看作一个“小池子”,然后用池化函数(如取最大值/平均值)来代表这一片区域。
2. 常见池化方法
(1) 平均池化 (Average Pooling)
- 输出 = 窗口内所有像素的平均值
- LeNet-5 使用的就是这种方式
- 特点:保留整体趋势,但细节容易被“冲淡”
(2) 最大池化 (Max Pooling)
- 输出 = 窗口内像素的最大值
- AlexNet 采用的方式
- 特点:突出最显著的特征(如边缘、角点),对背景噪声更鲁棒
(3) 全局平均池化 (Global Average Pooling, GAP)
- 对整个特征图取平均,得到单个数值
- GoogLeNet 开始流行,用于代替全连接层,减少参数
3. 池化的作用
- 降采样:减少特征图大小和参数量
- 平移不变性:即使目标在图像里稍微移动,池化后的特征变化不大
- 抑制噪声:尤其是最大池化,能忽略弱特征,强化显著特征
4. LeNet vs AlexNet 的对比
- LeNet (1998):用 平均池化 (average pooling),更偏“平滑”
- AlexNet (2012):改用 最大池化 (max pooling),保留了更强的边缘和纹理特征,识别效果显著提升。
3.随机丢弃Dropout
Dropout(随机失活/随机丢弃) 是 AlexNet 中首次大规模应用的一种正则化方法,提出的动机是为了缓解深度神经网络容易出现的 过拟合 问题。它的做法很直观:在训练过程中,按照一定概率 p(通常取 0.5)随机“丢弃”部分神经元及其连接,不让它们参与本次前向传播和反向传播,相当于临时把这些神经元屏蔽掉。这样每一次训练迭代时,网络结构都不完全一样,更像是训练了很多不同的子网络。由于这些子网络共享权重,最后整体效果相当于在做一种“模型集成”,能显著提高网络的泛化能力。
在实际实现时,Dropout 只在训练阶段起作用,测试阶段则恢复所有神经元,但会把权重按丢弃概率缩放,使得输出的期望保持一致。AlexNet 正是因为采用了 Dropout,有效缓解了当时训练大规模网络时严重的过拟合问题,才能在 ImageNet 上取得远超传统方法的表现。
4.数据扩增Data Augumentation
AlexNet 用的 ImageNet 数据集已经有 120 万张标注图片,在当时算是非常庞大的训练集了。但即便如此,这样一个 拥有 6000 万参数 的深度卷积神经网络,依然容易 过拟合。原因有两个:
第一,网络容量太大。
AlexNet 的参数规模比以往的模型大得多,它有能力“记住”训练数据里的很多细节甚至噪声。如果没有更多样化的数据,它在测试集上就会表现下降。
第二,样本分布不够“丰富”。
虽然 ImageNet 总量大,但对每个类别来说,图片的采集场景有限:
- 大部分照片拍摄角度类似
- 光照条件相对单一
- 物体位置、比例变化不够多
这会导致网络学习到的特征偏向于这些“训练集特定的分布”,泛化能力不足。
因此,数据增强(Data Augmentation)就显得非常重要。AlexNet 里采用的增强方法主要有:
- 随机裁剪:从原始 256×256 图像中随机裁出 224×224 的区域,增加平移与缩放的变化。
- 水平翻转:随机把图片左右翻转,让模型学会对称性。
- RGB 通道扰动:对颜色做轻微变化,模拟不同光照环境。
这些操作能在 不增加人工标注成本 的前提下,成倍地产生新的训练样本。这样一来,网络不仅见过“猫的正面照片”,也见过“猫的翻转照片”;不仅见过“光线好的苹果”,也见过“偏暗的苹果”。最终效果就是 提升泛化性能,降低过拟合。
5.GPU并行训练
在 2012 年的时候,深度神经网络的规模已经远远超出了普通 CPU 的承载能力。AlexNet 大约有 6000 万参数、6.5 亿连接,如果完全用 CPU 训练,可能要几个月甚至更久,几乎不可行。
Alex Krizhevsky 当时采用了 两块 NVIDIA GTX 580 GPU(每块显存 3GB) 来加速训练,并设计了一种 跨 GPU 的分工机制:
- 通道切分(channel split):每一层的特征图通道数被 平均分成两份,上面一半分配给 GPU1,下面一半分配给 GPU2。
- 卷积局部计算:大多数卷积操作只在“本 GPU 的通道子集”上完成,减少跨卡通信量。
- 有限的跨 GPU 连接:在某些层(如 Conv3、Conv4、Conv5)引入少量跨 GPU 的连接,用来保持特征的一致性。
这样做的好处是:
- 分担显存压力:当时的显存有限,把通道拆分能保证网络能放下。
- 并行计算:两个 GPU 同时运算,大幅缩短训练时间。AlexNet 最终用了 5~6 天 就在 ImageNet 上完成训练,而不是几个月。
- 工程上的突破:这是深度学习第一次真正利用 GPU 进行大规模卷积神经网络的训练,奠定了后面“GPU 是深度学习核心算力”的基础。
思考题:根据LeNet参数个数为61706个,计算ALEXNET每层参数的个数。
卷积层
- Conv1:11×11×3×96+96=34944
- Conv2(groups=2):每个核只连到上一层的一半通道 48
5×5×48×256+256=307456 - Conv3(不分组):3×3×256×384+384=885120
- Conv4(groups=2):3×3×192×384+384=663936
- Conv5(groups=2):3×3×192×256+256=442624
全连接层
- FC6(6×6×256=9216→4096):9216×4096+4096=37752832
- FC7(4096→4096):4096×4096+4096=16781312
- FC8(4096→1000):4096×1000+1000=4097000
总计
60965224
(≈ 6,096 万参数)
微信扫描下方的二维码阅读本文
