
SVM有三种方式处理多类问题(类别>2)
1.改造优化的目标函数和限制条件,使之能处理多类
2.一类VS其他类(一类对K-1类)K为类数 n个svm
3.一类VS另一类 n*(n-1)/2个svm
说直接点就是打分系统。
来看这个例子:
SVM1: 类1 VS 类2:0.5分
SVM2: 类1 VS 类3:-0.2分
SVM1: 类2 VS 类3:0.4分
打分结果:
类1:0.5-0.2=0.3
类2:-0.5+0.4=-0.1
类3:0.2-0.4=-0.2
聚类算法结合决策树算法 二分类器->多分类器
处理8个问题构建7个分类器:
1 2 3 4 vs 5 6 7 8
↓ ↓
1 2 vs 3 4 | 5 6 vs 7 8
↓ ↓ ↓ ↓
1vs2 | 3vs4 | 5vs6 | 7vs8
保证每个分类器区分的两类差别显著
思考:如果支持向量机的两类训练样本数量不平衡,将会导致什么样的结果?
1. 原始软间隔 SVM 目标函数
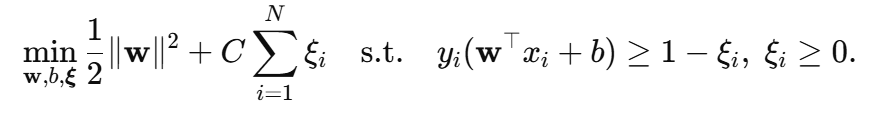
C 对所有松弛变量 ξi采用同一权重。
若正负样本数量极度失衡(设正类 N+≫N−),则惩罚项变为
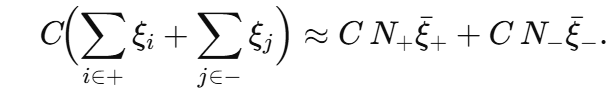
优化器更关心多数类(正类)的误差,因为它们数目多、总惩罚大。
2. 对偶形式验证
对偶问题(L1 损失):
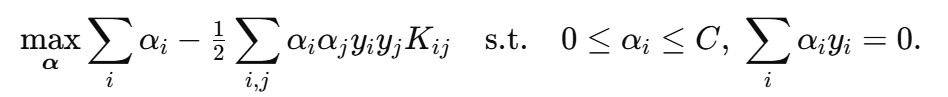
- 需要 ∑iαiyi=0(正负 α 总和抵消)。
- 如果正类样本太多,为满足平衡,正类 αi 往往被压得很小;少数类 αi必须较大才能抵消。这会把决策超平面推向少数类一侧,导致少数类更容易被误分类。
3. 典型现象
| 指标 / 现象 | 数学原因 | 结果表现 |
|---|---|---|
| 总体准确率高 | 多数类主导损失 | 看似效果不错 |
| 少数类召回低 | 少数类误分惩罚小 | 少数类经常被错分 |
| 支持向量分布 | 少数类 α 大、正类 α 小 | 支持向量数量失衡 |
| 决策面偏移 | 目标函数更“关心”多数类 | 间隔靠近少数类 |
4. 解决思路
(1)类别加权 Ci.
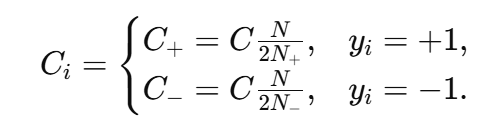
使每类样本的总惩罚相近,常用做法:class_weight='balanced'。
(2)重采样
对少数类进行过采样(如 SMOTE)或对多数类下采样。
(3)成本敏感 SVM
在目标函数显式写成 ∑iCiξi,手动设定重要度。
(4)阈值后移
训练模型保持原样,预测时使用 sign(f(x)−τ) 调整决策阈值。
(5)异常检测/一类 SVM
当少数类极少时,将其视为“异常”进行检测。
结论
样本数量不平衡会使支持向量机主要关注多数类误差,决策边界向少数类一侧偏移,从而降低少数类的识别率。通过类别加权、数据重采样或成本敏感学习等方法可有效缓解这一问题。
那么如何改造支持向量机的优化函数来缓解前面这个问题所带来的负面影响?
把“样本不平衡”写进 SVM 目标函数的三种经典改造
下面用最常见的 L1 软间隔 为例,若用 L2 软间隔或 ν-SVM、Twin-SVM,思路完全类似,只是公式里把 ∑ξi 换成 ∑ξi2 或者多一条超平面而已。
1️⃣ 类别加权 C+C_(最常用)
改造后的原始问题
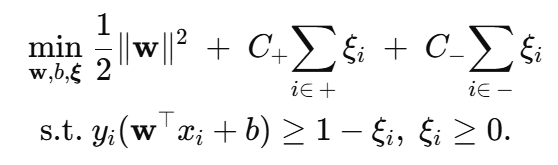
一般设
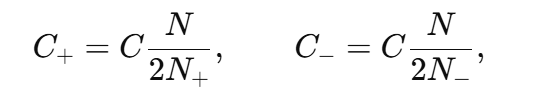
使两类误差对目标函数的总贡献相当。
对偶形式 0≤αi≤C+ 或 C−——上界因类别不同而不同,少数类 α 可以取到更大的值,进而推回更合理的超平面。
工程落地:
- libsvm:
-w1 ρ1 -w-1 ρ-1- scikit-learn:
class_weight='balanced'或传 dict{1:w1,-1:w-1}
2️⃣ 样本级权重 ω(Cost-Sensitive / Fuzzy SVM)
改造后的原始问题
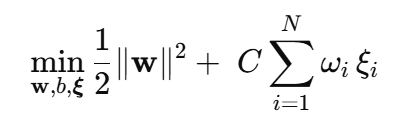
- ωi 可以
- 取 N/2Nyi(退化回类别权重);
- 根据样本置信度 / 噪声打分(Fuzzy SVM);
- 手工指定误分成本(Cost-Sensitive SVM)。
- 对偶: 0≤αi≤Cωi
好处:粒度更细,可对个别关键样本放大权重。
风险:权重极端时,会导致数值不稳定,需调参或归一化。
3️⃣ 调整间隔阈值(不同类别的 margin)
有时希望 正类 >1、负类 >1 的规定不一样,例如令少数类 margin 更大:
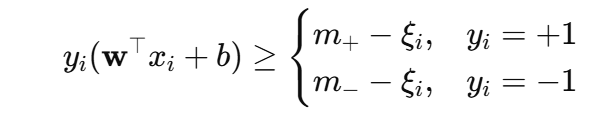
配合类别权重,这就是 Margin-Rescaling SVM:
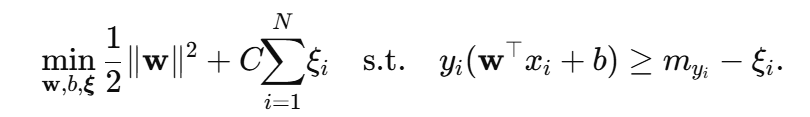
- 取 m+>m− 可强迫模型“远离”少数类,提高其识别率。
- 对偶约束仍是 0≤αi≤C,但 KKT 中出现 myi ——最终等价于重新平移阈值。
这些改造如何缓解问题?
| 改造 | 优化目标中发生了什么 | 直接效果 |
|---|---|---|
| 类别加权 C± | 多数类每错 1 个只罚 C+,少数类罚 C−≫C+ | 决策面远离少数类,召回↑ |
| 样本权重 ω | 惩罚项精确到样本 | 可针对局部稀疏区、极端样本加强影响 |
| margin 重缩放 | 少数类要求更大间隔 | 对偏移特别敏感的数据集更有效 |
参考代码:
from sklearn.svm import SVC
# 方法1:类别加权
model = SVC(kernel='rbf', class_weight='balanced', C=1.0)
# 方法2:自定义样本权重
sample_weights = np.where(y==1, N/(2*N_pos), N/(2*N_neg))
model = SVC(kernel='rbf', C=1.0)
model.fit(X, y, sample_weight=sample_weights)
# 方法3:自定义 margin(需改源码或用 PyTorch 自写 loss)
结论:样本数量不平衡会导致支持向量机的主要关注多数类误差,决策边界向少数类一侧偏移。从而降低少数类的识别率。通过类别加权、数据重采样或成本敏感学习等方法解决。
微信扫描下方的二维码阅读本文
