
支持向量机 (SVM) 是一种用于分类和回归任务的监督机器学习算法。它试图找到称为超平面的最佳边界,以分隔数据中的不同类。当您想要进行二元分类(例如垃圾邮件与非垃圾邮件或猫与狗)时,它很有用。
SVM 的主要目标是最大化两个类之间的余量。边距越大,模型在新的和看不见的数据上的性能就越好。
支持向量机的关键概念
- 超平面:在特征空间中分隔不同类的决策边界,在线性分类中用方程 wx + b = 0 表示。
- 支持向量:最接近超平面的数据点,对于确定 SVM 中的超平面和边距至关重要。
- 边距:超平面和支持向量之间的距离。SVM 旨在最大化此裕度以获得更好的分类性能。
- 内核:将数据映射到更高维空间的函数,使 SVM 能够处理非线性可分离数据。
- 硬边距:最大边距超平面,可完美分离数据而不会出现错误分类。
- 软边距:通过引入松弛变量来允许一些错误分类,在数据不可完全分离时平衡边距最大化和错误分类惩罚。
- C:平衡边际最大化和错误分类惩罚的正则化项。较高的 C 值会对错误分类进行更严格的处罚。
- 铰链损失:一种损失函数,用于惩罚错误分类的点或边距违规,并与 SVM 中的正则化相结合。
- 对偶问题:涉及求解与支持向量相关的拉格朗日乘数,促进内核技巧和高效计算。
支持向量机算法如何工作?
SVM 算法背后的关键思想是通过最大化两个类之间的边距来找到最能分隔两个类的超平面。该边距是从超平面到每侧最近的数据点(支持向量)的距离。
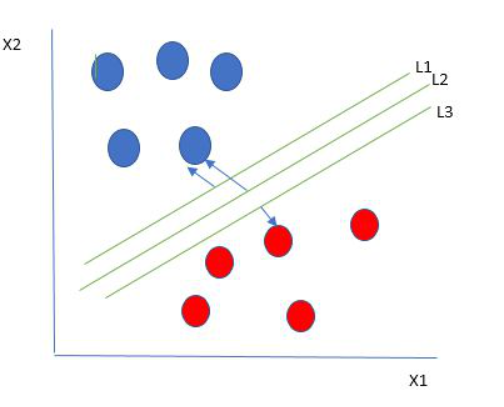
最佳超平面也称为“硬边距”,是最大化超平面与两个类中最近的数据点之间的距离的超平面。这确保了类之间的明确分离。所以从上图来看,我们选择 L2 作为硬边距。让我们考虑如下所示的场景:
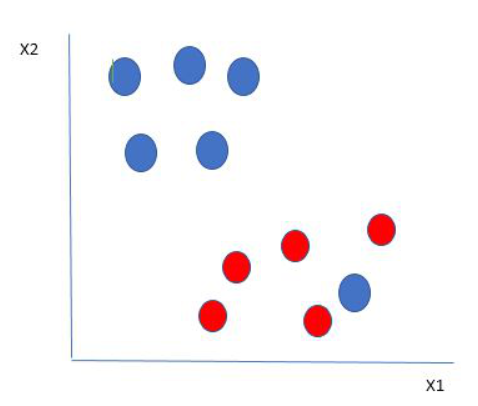
在这里,我们在红球的边界上有一个蓝球。
SVM 如何对数据进行分类?
红球边界中的蓝球是蓝球的异常值。SVM 算法具有忽略异常值并找到最大化余量的最佳超平面的特性。SVM 对异常值是鲁棒的。
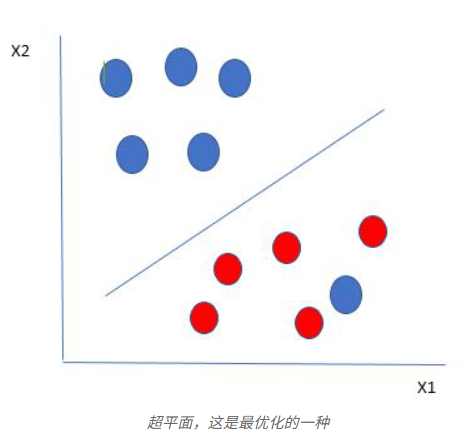
支持向量机 (SVM) 的优势
- 高维性能:SVM在高维空间中表现出色,适用于图像分类和基因表达分析。
- 非线性能力:利用 RBF 和多项式 SVM 等核函数可以有效处理非线性关系。
- 异常值弹性:软边距功能允许 SVM 忽略异常值,从而增强垃圾邮件检测和异常检测的稳健性。
- 二进制和多类支持:SVM 对二进制分类和多类分类都有效,适用于文本分类中的应用。
- 内存效率:它专注于支持向量,与其他算法相比具有内存效率。
支持向量机 (SVM) 的缺点
- 训练速度慢:对于大型数据集,SVM 可能会很慢,从而影响 SVM 在数据挖掘任务中的性能。
- 参数调整难度:选择正确的内核并调整 C 等参数需要仔细调整,这会影响 SVM 算法。
- 噪声敏感性:SVM 难以应对嘈杂的数据集和重叠的类,从而限制了现实场景中的有效性。
- 有限的可解释性:高维度超平面的复杂性使得 SVM 的可解释性低于其他模型。
- 特征缩放灵敏度:适当的特征缩放至关重要,否则 SVM 模型可能会表现不佳。
微信扫描下方的二维码阅读本文
