[1]The hickory (Carya cathayensis) nuts are considered as a traditional nut in Asia due to nutritional components such as phenols and steroids, amino acids and minerals, and especially high levels of unsaturated fatty acids.
[2]Furthermore, a mature hickory nut kernel contains more than 90% unsaturated fatty acids and 70% oil, which is in the top place in all oil-bearing crops (Kurt, 2018; Narayanankutty et al., 2018; Zhenggang et al., 2021).
[3]In Lin’an, the hickory plantation covers an area of 40,000 km2, with an annual production of 15,000 tons of hickory nuts. The output value of the whole hickory nuts industry is about 5 billion yuan.
[4]However, the edible quality of hickory nuts is rapidly deteriorated by oxidative rancidity.
[5]With the oxidation of hickory nuts, a series of changes in color,odor, taste, and other conditions occur. Significantly the kernels of hickory nuts change from light yellow to yellow-brown or brown,the taste gradually becomes lighter and lighter, and a strong rancid smell from the nuts (Jiang et al., 2012).
[6]Traditional methods of identifying hickory nuts are mainly manual and electronic nose screening (Pang et al., 2011).
[7]However, electronic nose technology has a slow response time and requires special equipment, making it difficult to promote in the marketplace.
The workflow of Vision Transformer (VIT; Dosovitskiy et al., 2020) firstly requires dividing the original image into several regular non-overlapping blocks and spreading the divided blocks into a sequence, after which the sequence is transmitted into the Transformer Encoder.
However, the structure based on the Transformer does not obtain better results by simply stacking it like the convolutional networks (CNN)structure. Instead, it quickly sinks into saturation at deeper levels. That is called attention collapse (Zhou et al., 2021).
Re-attention (Equation 4) could replace the MHSA module in the VIT and regenerate the attention maps to establish crosshead communication in a learnable way.
Firstly, unlike VIT, MAE and DeepVIT, the blocks sequence input to DEEPMAE is not from the original image but is composed of low-level features extracted from the original image by convolutional operations.
Therefore, we change the patch embedding of DEEPMAE to an operation with multiple small convolutional kernels and convert the low-level features of the acquired images into patches, similar to the Image-to-Tokens module (Yuan et al., 2021).
[2]
DEEPMAE combines self-supervised and supervised learning, which are usually considered two different approaches, into a single unified model. And DEEPMAE outperformed the base MAE model in classifying hickory nuts kernels. Furthermore,the DEEPMAE model is lighter. It uses fewer parameters to achieve better results.
In addition, unlike MAE, which uses only the trained parameters of the Encoder when processing classification tasks, our DEEPMAE always retains both Encoder and Decoder and combines the reconstruction of image features and classification into one complete model.
The classification is a supervised learning. Eventually, the complete structure of DEEPMAE contains both self-supervised and supervised processes.
[3]
Re-attention (Equation 4) could replace the MHSA module in the VIT and regenerate the attention maps to establish crosshead communication in a learnable way.
Secondly, we introduce Re-attention into MAE, reduce the MAE model width, and increase its depth to achieve a deeper stacking of the Transformer to obtain a more vigorous representation of some of the blocks, which can reduce the computational effort while avoiding attention collapse.
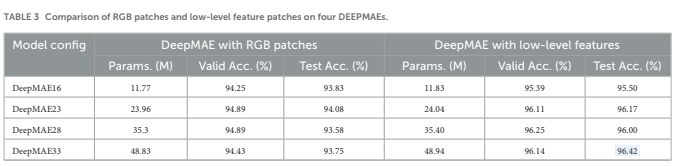
The DEEPMAE model was able to achieve an overall classification accuracy of 96.14% on the validation set and 96.42% on the test set.
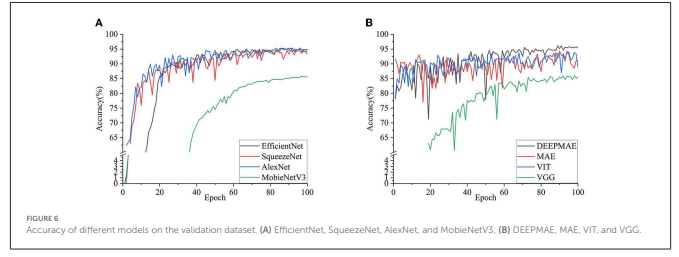
From the accuracy performance of each model in the validation set (Figure 6), it is easy to see that the MobileNetV3 and VGG19 models performed average level. They were slow to optimize, and their final accuracy was just over 80%.
These values appear to be the main features learned by DEEPMAE to distinguish walnuts, such as their appearance brightness and color.
In addition, by aggregating information from image samples, we have confirmed that the critical features learned by DEEPMAE are precisely the brightness and color of the appearance of kernels.
It shows that the range of L-values of D in AL is much smaller than in Figure 5A, resulting in images of D being largely misclassified as adjacent C. The ranges of b-values of B, C, and D are closely linked, indicating that C of Figure 11 was misclassified as B and D. After adjusting the L-value or b-value of images, the results of DEEPMAE demonstrated a strong relationship between the data distribution and the classification effect, indicating that the L-value or b-value characteristics are of great importance for the classification process of DEEPMAE.