
本期评述文章:
这篇论文的核心在于解决一个痛点:甘薯疮痂病在早期很难通过肉眼(RGB)识别,所以作者利用高光谱成像(HSI)技术,结合机器学习算法,试图在人眼看到症状之前就检测出病害 。
开始之前-实验设计
在这篇论文中,作者为了让计算机学会“看”出人眼看不到的早期病害,精心设计了一个“找不同”的实验。
我们可以把这个实验设计拆解为三个关键环节。
- 🍠 “双薯记”:为什么选这两个品种?(样本选择) 他们特意选取了两个极端:抗病品种(广薯87)和感病品种(贵菜薯2)。为什么要这样做?这对于训练模型有什么特殊的帮助?
- 📸 “高科技摄影棚”:怎么拍出光谱图?(数据采集) 他们没有在田间地头拍,而是把红薯搬进了全黑的实验室,用卤素灯和高光谱相机拍摄 。这种“摆拍”是为了消除什么干扰?
- ⏱️ “时间猎人”:如何捕捉“早期”?(数据分组与时间轴) 他们连续监测了 8 天,并且人为地定义了“早期潜伏期”和“早期轻度期” 。这部分设计直接决定了论文的核心创新点。
🍠 “双薯记”:为什么选这两个品种?(样本选择)
Experiments were conducted using the sweet potato scab-resistant variety Guangshu 87 (GS87) and the susceptible variety Guicaishu 2 (GCS2).
Trans:本实验采用抗甘薯疮痂病品种广薯87(GS87)和易感品种贵菜薯2(GCS2)进行。
这个实验设计的核心逻辑是“控制变量法”的极致应用。作者没有只选一种容易得病的红薯,而是特意引入了一个“陪跑”的抗病品种。
1. 选角:为什么是这两种红薯?
作者选择了两个性格迥异的品种:
- 易感品种 (Susceptible):贵菜薯2号 (GCS2)。它是主角,因为它容易得病,光谱变化明显,用来训练模型识别病害。
- 抗病品种 (Resistant):广薯87 (GS87)。它是配角,但至关重要。
💡 深度思考:为什么要选抗病品种?
如果只用易感品种,当光谱发生变化时,你很难 100% 确定这是由疮痂病菌引起的,还是因为喷水(接种过程)、套袋保湿等操作引起的应激反应。
通过引入抗病品种,作者发现:在接种后,抗病品种 GS87 的光谱几乎没有显著变化(p=0.535),而易感品种 GCS2 的红边波段变化显著(p=0.039)。
结论: 这证明了光谱的变化确实是由病害感染引起的,而不是环境或操作误差。这为后续的数据分析提供了铁证。
2. 分组:严谨的“四象限”
为了万无一失,作者将这 12 株红薯分成了 4 组 :
The two sweet potato varieties, resistant and susceptible, were divided into a control group and a treatment group, with three replicates in each group, totaling twelve plants
Trans:将抗病与易感两种甘薯品种分为对照组和处理组,每组设三个重复,共计十二株植株。
- GCS2 (易感) - 对照组 (CK):健康的,没病的。
- GCS2 (易感) - 处理组 (T):接种了病菌的(这是我们要检测的目标)。
- GS87 (抗病) - 对照组 (CK):健康的。
- GS87 (抗病) - 处理组 (T):接种了病菌,但因为它抗病,所以它是用来验证“光谱稳定性”的。
3. 接种:模拟真实的“生病”过程
为了让数据可控,他们没有等自然发病,而是进行了人工接种。
- 病原体:从感染的红薯叶片上分离出的 Elsinoë batatas 真菌。
- 操作:配制成孢子悬浮液喷洒在叶片上,然后套袋保湿,模拟高湿度的感染环境(25°C, 90% 湿度)。
🧐 这里的“坑”与“对策”
你可能会注意到,一共只有 12 株 植物(每组 3 个重复)。
- 问题:作为机器学习的数据集,12 株样本太少了,容易导致模型过拟合(Overfitting),也就是模型只记住了这几棵草的样子,换一棵就不认识了。
- 对策:这就是为什么后面会有 ROI(感兴趣区域)提取 和 数据增强(Data Augmentation) 的原因。作者通过从每张图提取 5-10 个光谱组,把样本量扩充到了 527 个原始数据,后面又通过加噪声等方法进一步扩充。
📸 “高科技摄影棚”:怎么拍出光谱图?(数据采集)
如果说“双薯记”是为了选对演员,那么这个环节就是为了搭建最完美的舞台。对于高光谱成像来说,光环境的纯净度决定了数据的生死。如果环境光乱糟糟,或者阴影太多,任何微小的光谱信号都会被噪音淹没。
作者是如何搭建这个“无菌”的光学环境的?我们可以从硬件配置、拍摄几何和数据清洗三个层面来拆解:
1. 硬件配置:全黑屋与特定的光
这也是为什么做高光谱研究通常不能直接在田里拍,而要进实验室的原因。
- 全黑环境 (Darkroom):实验是在一个光控室里进行的,严格隔绝了自然光。
- 为什么? 太阳光是不稳定的(有云飘过光强就会变),而这里需要绝对稳定的光源,确保每一天拍摄的数据具有可比性。
- 特定光源:使用了两盏 500W 的卤素灯。
- 为什么? 卤素灯的光谱覆盖范围很宽(可见光到近红外),非常平滑,非常适合做高光谱照明。
- 拍摄设备:SOC710-VP 高光谱成像仪。
- 能力值:它的光谱范围是 400-1000 nm(覆盖可见光和近红外),光谱分辨率高达 2.1 nm,一共有 128 个波段。这意味着它把我们肉眼看到的“红色”,细分成了几十种不同的“红”。
2. 拍摄几何:45度角的秘密
作者对灯光和相机的位置做了非常精确的规定:
The camera was mounted horizontally on a tripod, positioned 0.4 m above the potted sweet potato samples, and illuminated by two 500 W halogen lamps placed at a 45 degree angle. The setup remained fixed throughout the imaging cycle, with samples photographed against a white background.
Trans:相机水平安装在三脚架上,距离盆栽甘薯样品上方0.4米,并由两盏500瓦卤素灯以45度角照射进行照明。在整个成像过程中,装置保持固定,样品在白色背景下拍摄。
- 位置:相机垂直向下,距离红薯 0.4 米。
- 灯光角度:两盏灯呈 45度角 照射样品。
- 为什么是45度? 这个角度是经典的翻拍布光方式,可以最大程度地减少叶片表面的镜面反射(反光),同时避免阴影过重。对于表面有蜡质的红薯叶片来说,减少反光至关重要。
- 背景:使用了白色背景。这主要是为了方便后期用软件把绿色的叶子“抠”出来(ROI提取)。
3. 数据清洗:把“图像”变成“数据” (校正)
拍出来的原始照片其实是不能用的,因为里面包含了光源的亮度和相机的暗电流噪声。必须进行辐射校正,把它们转化为反射率 (Reflectance)。
论文中给出了一个核心公式,这是所有光谱分析的“起手式” :
- Iraw (Raw Image): 刚才拍到的原始红薯图像。
- Idark (Dark Current): 盖上镜头盖拍一张全黑的图。这代表了相机电子元件自带的热噪声,必须减掉。
- Iwhite (White Reference): 拍一块标准的白板(反射率接近100%)。这代表了当时光照的“最大值”。
这一步的意义:
The process of converting digital number (DN) values to reflectivity enhances the interpretation of hyperspectral data, as reflectivity more accurately represents the chemical properties of the observed objects.
Trans:将数字值 (DN) 转换为反射率的过程增强了对高光谱数据的解释,因为反射率能更准确地表示被观测物体的化学性质。
通过这个公式,不管灯泡稍微变暗了一点,还是相机稍微变热了一点,都被这个比例运算抵消了。最终得到的 R (反射率),才是红薯叶片真实的物理属性,才具有生物学意义。
👉 总结一下:
作者在这个环节做到了极致的“标准化”。
- 环境标准化:全黑屋+卤素灯。
- 操作标准化:固定拍摄高度和角度。
- 数据标准化:黑白板校正。
正是因为有了这套高质量、低噪声的纯净数据,他们才敢在接下来的环节中,去挑战那个肉眼看不见的任务——动态分级(捕捉早期潜伏期)。
⏱️ “时间猎人”:如何捕捉“早期”?(数据分组与时间轴)
动态分级方法的创新 (The "Novelty") 💡 论文提出了一个“光谱-时间动态分级方法”(Dynamic Grading Method)。我们可以探讨他们是如何不依赖传统的人工经验,而是利用光谱数据的变化来定义“早期潜伏期”和“早期轻度期”的。这是本文的一大亮点 。
这个环节是实验成功的关键。因为“早期”是一个模糊的时间概念,如果靠人眼看,可能第 5 天才看到斑点,那时候黄花菜都凉了。
作者在这里使用了一种“用数据定义时间”的策略。
我们可以把这个过程想象成每天给红薯做一次“全身CT”(高光谱扫描)。 每一天,他们都会拿接种组(T)的光谱去和健康组(CK)的光谱“找不同”。
为了量化这个“不同”,作者引入了一个关键指标:显著性波段比例(Significant Band Ratio)。
- 简单来说,就是看那 116 个波段里,有多少个波段的数值在统计学上(p<0.05)是不一样的。
根据论文的描述(特别是关于“早期潜伏期”的定义),在接种后的 第 1 天 发生了什么特殊的现象,让作者断定“潜伏期”已经开始了?
On Day 1, the proportion of significant bands exceeded 50%, and Day 1 was chosen as the classification point between the early incubation period and the control group.
Trans:在第 1 天,显著性波段比例超过 50%,因此选择第 1 天作为早期潜伏期和对照组之间的分类点。
这意味着,尽管在接种后的第 1 天,红薯叶子在肉眼看来还非常健康(没有任何病斑),但在高光谱相机的“火眼金睛”下,超过一半的光谱波段已经和健康组产生了统计学上的显著差异 。
这就是作者如何用数据“抓”住“早期潜伏期” (Early Latent Period) 的:
- 逻辑:只要显著差异波段占比 > 50%,就说明内部生理结构已经发生了剧烈变化,虽然外表看不出来。
🔍 下一步:寻找“早期轻度期” (Early Mild Period)
随着时间推移,病害进一步发展。但作者发现了一个非常有意思的现象:光谱的差异并不是一直变大的。
请看看论文的 Figure 7(第 10 页)或者 3.2 节的后半段 。
作者观察到,在第 3 天差异达到高峰后,到了 哪两天,光谱的显著差异比例反而出现了明显的下降(decreased)?
作者正是利用这个“差异变小/趋于稳定”的现象,来定义“早期轻度期”开始的。你能找到是哪两天吗?
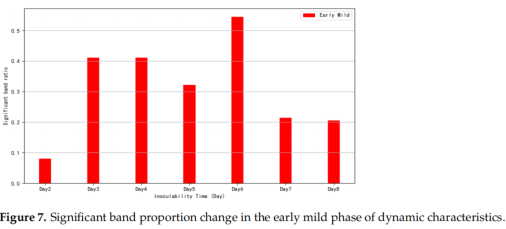
Figure 7 presents a day-to-day comparison within the treatment group. The proportion of significant bands on Day 3, Day 4, and Day 6 exceeded 40%, with Day 6 showing more than 50%. As spectral differences diminished, it can be inferred that the disease had reached short-term stability and entered the next disease stage. The spectral differences significantly decreased after Day 4 and Day 6, indicating that these time points mark the onset of the early mild period.
Trans:图 7 展示了治疗组内每日的比较结果。第 3 天、第 4 天和第 6 天显著谱带的比例均超过 40%,其中第 6 天的比例超过 50%。随着光谱差异的减小,可以推断疾病已达到短期稳定期并进入下一阶段。第 4 天和第 6 天之后光谱差异显著降低,表明这些时间点标志着早期轻症期的开始。
在 第4天 和 第6天 之后,光谱差异显著下降 。
这在生物学上意味着什么呢?作者认为这表明病害进入了一个 “短期稳定状态” (short-term stability) 。也就是说,病原菌和植物的免疫系统可能暂时达成了一种“僵持”,导致生理变化(以及光谱特征)不再剧烈波动。
于是,作者就利用这个数据特征,把这两个时间点作为 “早期轻度期” (Early Mild Period) 的开始。
🧩 实验设计小结
到目前为止,我们已经复盘了他们极其严谨的实验逻辑:
- 样本:用“抗病 vs 感病”品种做对照,证明光谱变化是病引起的。
- 环境:用“全黑屋+45度光”保证数据纯净。
- 时间:用“光谱差异比例”的波动,客观定义了肉眼看不见的“潜伏期”和“轻度期”。
有了这些打好标签的高质量数据,下一步就是怎么把它们喂给 AI 模型了。
技术路线与数据处理 (The "How")
🛠️ 重点关注他们是如何处理高光谱数据的。比如如何进行去噪(MSC, SG)、降维(PCA),以及通过随机森林(RF)筛选特征波段。这是复现实验或设计你自己算法的基础 。
高光谱数据有一个巨大的问题:维度灾难(116个波段,数据量大且有冗余)。直接扔进模型里效果通常不好。
作者在这里做了两步关键操作:去噪 (Preprocessing) 和 降维/特征提取 (Dimensionality Reduction)。
我们先看 去噪。作者比较了三种常用的平滑/校正算法:SG, MA, 和 MSC。 请看 Figure 8 (第 10 页) 或者 3.3 节。你能看出他们最终选了哪一种方法吗?为什么选它?
Savitzky-Golay (SG) smoothing, moving average (MA) filtering, and multivariate scattering correction (MSC) were applied to the spectral data of the susceptible variety GCS2 in both the control and treatment groups. Based on the spectral-time dynamic grading method, the treatment group was classified into appropriate disease stages. After testing the performance of each method, the MSC method was selected due to its superior prediction effect in subsequent modeling.
Trans:对易感品种GCS2的对照组和处理组光谱数据分别应用了Savitzky-Golay (SG)平滑、移动平均(MA)滤波和多元散射校正(MSC)方法。基于光谱-时间动态分级方法,将处理组划分为相应的疾病阶段。在测试了各方法的性能后,由于MSC方法具有更优的预测效果,因此选择其进行后续建模。
文中明确提到,经过对比测试,MSC(多元散射校正) 因为在后续建模中表现出最好的预测效果,所以被选为了最终的预处理方法 。
💡 为什么是 MSC? 这里有个很重要的背景知识:在拍摄植物叶片时,叶片表面的纹理不均匀或者颗粒分布会导致光线产生复杂的散射。这种散射会像“雾”一样遮挡住我们要找的病害信号。MSC 就像一副“去雾眼镜”,专门用来校正这种散射效应 ,从而还原出叶片真实的化学光谱特征。
📉 第4个环节:破解“维度灾难” (降维与特征选择)
现在,数据已经很“干净”了,但我们还面临一个巨大的挑战:116 个波段。
- 冗余:比如 800nm 和 801nm 的数据可能长得几乎一样(相关性太高)。
- 干扰:有些波段可能根本不包含病害信息,放进模型只会捣乱。
为了把这 116 个特征浓缩成精华,作者用了两套截然不同的策略:
- PCA (主成分分析)
- RF (随机森林特征选择)
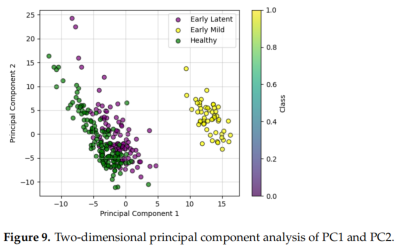
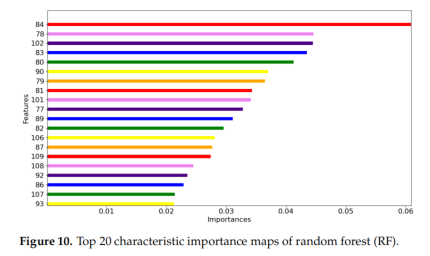
请看看 Figure 9 和 Figure 10 。
- 🤔 思考题: 虽然这两种方法都能让特征变少,但它们的产出结果有着本质的区别。你能告诉我:哪一种方法是创造了全新的“合成变量”,而哪一种方法只是从原始数据里“挑选”了几个最重要的波段?
- PCA创造全新的合成变量,RF从原始数据里“挑选”几个最重要的波段
这就是两者的核心区别:
- PCA (主成分分析) 就像把所有水果扔进搅拌机做成混合果汁 🥤。虽然营养(信息)都在,但你很难分清哪一口是苹果,哪一口是香蕉。它的优点是极致的压缩(只用 PC1 和 PC2 就能代表 67% 的变异信息 ),但缺点是丢失了物理意义(你不知道具体是哪个波段在起作用)。
- RF (随机森林) 就像在水果摊上挑水果 🍎。它直接告诉你:“第 84 号波段(801.8 nm)最重要!”。这对于农业研究非常宝贵,因为我们只要知道这几个特定波段,未来就可以开发便宜的便携式传感器,而不需要昂贵的全光谱相机。
模型对比与结果分析 (The "Result") 📊
对比 SVM、KNN 和 LDA 这几种模型在不同特征提取方法下的表现。我们可以看看为什么在这个特定任务中,PCA-SVM 模型的效果最好(准确率高达 98.65%) 。
📊 终极对决:谁是“诊断之王”?
现在我们手头有两套特征:
- PCA组:混合后的主成分。
- RF组:挑选出的 15 个“明星”波段 。
作者把它们分别“喂”给三个经典的机器学习分类器:SVM (支持向量机)、LDA (线性判别分析) 和 KNN (K近邻)。
请看看 Table 4(第 13 页)或者 3.5 节的文字描述 。
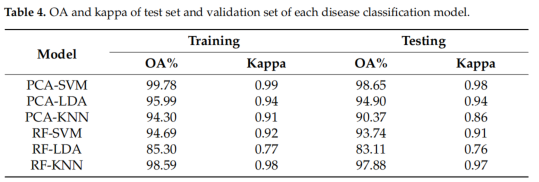
- 在这个“3x2”的比赛中(3个模型 x 2种特征提取),哪一个组合拿到了最高的测试集准确率(Overall Accuracy)?它的准确率达到了多少?
- PCA-SVM准确率最高,达到了98.65%
🏆 PCA-SVM 模型确实是冠军,测试集准确率达到了惊人的 98.65% 。
这说明在这个研究中,把所有波段的信息“揉碎”了融合在一起(PCA),比单纯只挑几个“明星波段”(RF)更能准确地捕捉到病害的特征。
到这里,我们已经把这篇论文的核心“骨架”都拆解完了:
- 样本:抗病 vs 感病,确立对照。
- 数据:全黑屋 + 45度光,保证质量。
- 核心创新:用光谱差异的统计学规律,定义了肉眼看不见的“早期”。
- 结果:MSC去噪 + PCA降维 + SVM分类,效果最好。
- 作者非常诚实地提到了这项研究的一个主要局限性(Limitations),这关乎到这个技术能不能真的用到田间地头。你能找到这个局限性是什么吗?(提示:这就回到了我们一开始讨论的“摄影棚”环境)
- 局限性是光照环境导致的偏差。
实验室里的环境是“温室里的花朵”:光照稳定、背景纯净(白色)、角度完美(45度)。但如果把这套系统搬到真实的农田里,就会遇到各种挑战,比如阳光强度的变化、云层的遮挡、叶片互相遮挡产生的阴影等等。
这就是所谓的 “实验室到田间的鸿沟” (Lab-to-Field Gap),也是目前很多农业 AI 研究面临的最大瓶颈。
- 作者为了解决这个问题,在论文末尾提出了几个未来的改进方向(Future Work)。你能找到他们打算怎么做来让这项技术更接地气吗?
- 开发低成本的高光谱传感器,用于田间部署
Despite its high accuracy, this study has limitations. The controlled environment used in the experiments could introduce bias, as they were conducted indoors under stable lighting conditions. Field validation is necessary to account for environmental variability.
Additionally, the current model focuses on E. batatas, and future work should extend to other sweet potato pathogens (e.g., Fusarium spp.). To address these issues, we plan to develop low-cost hyperspectral sensors for field deployment, expand the dataset to include multiregional sweet potato varieties, and explore fusion with thermal or LiDAR data for multimodal disease assessment.
Trans:尽管本研究具有较高的准确性,但仍存在局限性。实验采用的室内稳定光照环境可能导致偏差,因此需要通过实地验证来消除环境差异的影响。
此外,当前模型主要针对甘薯真菌病害,未来研究应扩展至其他甘薯病原体(如镰刀菌属)。为解决这些问题,我们计划开发低成本高光谱传感器用于田间部署,扩充数据集以涵盖多区域甘薯品种,并探索与热成像或激光雷达数据融合,实现多模态病害评估。
作者明确提出,未来的目标是开发低成本的高光谱传感器,以便在田间大规模部署 。这是将这项“贵族技术”变成“平民工具”的关键一步。
------
生成式人工智能声明:本文在创作过程中使用了Gemini 3。
微信扫描下方的二维码阅读本文
