
本期评述文章:
它针对一个很实际的农业生产问题——如何用少量样本准确识别植物病害,提出了一种新的算法。
Plant disease recognition based on computer vision can help farmers quickly and accurately recognize diseases. However, the occurrence of diseases is random and the collection cost is very high. In many cases, the number of disease samples that can be used to train the disease classifier is small.
Trans:基于计算机视觉的植物病害识别技术能帮助农民快速准确地识别病害。然而,病害发生具有随机性,且采集成本较高。在多数情况下,可用于训练病害分类器的样本数量有限。
根据论文摘要(第1页),作者指出,虽然计算机视觉对识别植物病害很有帮助,但收集大量标记好的病害图片样本既困难又昂贵。 这对需要海量数据的传统深度学习方法来说是个大挑战。
为了解决这个问题,他们提出了一种分为两个阶段的算法 :
Our algorithm is divided into two phases: supervised contrastive learning and meta-learning. In the first phase, we use a supervised contrastive learning algorithm to train an encoder with strong generalization capabilities using a large number of samples. In the second phase, we treat this encoder as an extractor of plant disease features and adopt the meta-learning training mechanism to accomplish the few-shot disease recognition tasks by training a nearest-centroid classifier based on distance metrics.
Trans:我们的算法分为两个阶段:监督对比学习和元学习。在第一阶段,我们采用监督对比学习算法,通过大量样本训练具有强泛化能力的编码器。第二阶段,我们将该编码器作为植物病害特征提取器,通过基于距离度量的最近质心分类器训练机制,运用元学习训练方法完成
- 第一阶段:使用“监督对比学习” (Supervised Contrastive Learning) 和大量样本来训练一个具有强大泛化能力的编码器(encoder)。
- 第二阶段:将这个编码器作为特征提取器,并采用“元学习” (Meta-learning) 机制,通过训练一个最近质心分类器来完成“小样本” (few-shot) 的识别任务。
这里有几个切入点:
- 弄清关键“术语”:这篇论文的标题和摘要中提到了好几个关键概念,比如“监督对比学习” 和“元学习” 。
- 深入理解“问题”:论文在引言(Introduction)部分详细讨论了为什么传统深度学习方法不适用于这个问题。我们为什么不先从这里开始,搞清楚“小样本学习” (Few-shot Learning) 究竟要解决什么?
- 拆解“解决方案”:论文的核心是他们提出的两阶段方法 。我们可以直接去看图1(第4页),它清晰地展示了“监督对比预训练”和“最近质心分类”这两个阶段是如何协同工作的。
1.弄清关键“术语”
我们来逐个分解这两个核心术语。
1. 监督对比学习 (Supervised Contrastive Learning)
Contrastive learning is usually a self-supervised learning method,which pre-trains a model with a large amount of unlabeled data tolearn feature representation.
Trans:对比学习通常是一种自监督学习方法,该方法通过大量未标注数据对模型进行预训练,使其学习特征表示。
- 这是什么? 它是一种“预训练” (pre-training) 方法,目标是训练出一个能出色区分不同类别图像的“编码器” (Encoder)。
- 它如何工作?
- “对比” (Contrastive) 的意思是,它通过“对比”样本来学习。它会拉近“相似”的样本,推远“不相似”的样本。
- “监督” (Supervised) 的意思是,它会利用图像的“标签” (label) 信息(比如,知道哪些图片是“苹果黑星病”,哪些是“玉米灰斑病”)。
- 拉近正样本:所有“同类”的图像(比如,所有“苹果黑星病”的图片)都应该在特征空间中靠得更近。
- 推远负样本:所有“不同类”的图像(比如,“苹果黑星病”和“玉米灰斑病”的图片)都应该在特征空间中离得更远。
2. 元学习 (Meta-learning)
- 这是什么? 这是一个更广泛的概念,常被用于小样本学习 (FSL)。它的核心思想是“学会如何学习” (learning to learn)。
- 它如何工作?
- 传统机器学习是“学会一个任务”(比如,分类猫和狗)。
- 元学习是“学会快速掌握新任务”。它会通过大量不同的先验任务进行训练,目标是找到一个好的模型“初始状态”。
- 当模型遇到一个全新的、只有很少样本的任务时(比如,识别一种从未见过的植物病害),它能从这个“初始状态”出发,仅用几张图片就快速学会。
在这篇论文中,作者将两者巧妙地结合了起来:
- 他们用监督对比学习(第1阶段)来完成“元学习”中的“预训练”过程,目的是学到一个泛化能力极强的编码器(特征提取器)。
- 然后,他们在这个编码器的基础上,用一个最近质心分类器(第2阶段)来执行具体的小样本识别任务,这体现了元学习“快速适应新任务”的机制。
现在我们弄清了这两个关键概念,你希望接下来做什么?
- 深入了解第一阶段:看看“监督对比学习”的具体算法流程是什么样的?(参考图1上半部分和算法1)
- 深入了解第二阶段:看看“最近质心分类器”是如何利用第一阶段的成果进行小样本分类的?(参考图1下半部分和图3)
- 回到“问题”本身:我们已经知道了术语,那回头看看引言(Introduction)部分,更深入地了解一下为什么“小样本学习” (FSL) 在植物病害领域如此重要?
2.深入了解 第一阶段
2.1监督对比预训练 (Supervised Contrastive Pre-training)。
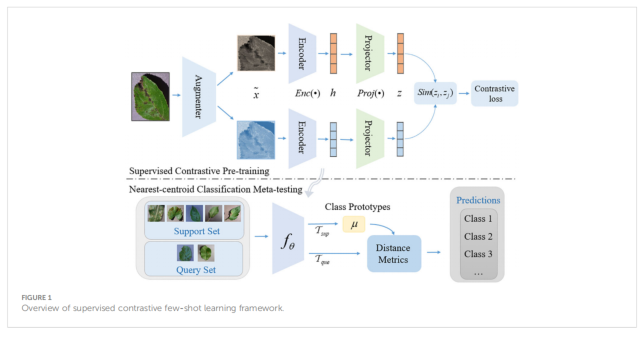
我们可以参照图 1(第4页) 的上半部分来理解这个流程。
- 数据增强 (Augmenter):
- 我们从一张病害图片开始。
- 这张图片会经过“Augmenter”(数据增强器),生成两个随机变换过的版本(比如,一张被裁剪,另一张调整了颜色)。 论文称这两个版本为“正样本对” (positive pair)。
- 编码器 (Encoder):
- 这两个增强后的图片,被送入同一个编码器网络(Enc(·))。
- 编码器的作用是将每张图片转换成一个特征向量(一串数字),论文中用 h 表示。这就像是模型对图片内容的“浓缩理解”。
- 投影仪 (Projector):
- 上一步得到的特征向量 h 会再经过一个“Projector”(投影网络, Proj(·))。
- 这会把 h 映射到另一个特征空间,得到向量 z。 这么做的目的是为了计算对比损失。
- 对比损失 (Contrastive loss):
- 这是最关键的一步。算法会比较来自不同图片的 z 向量。
- 正如我们之前讨论的,因为这是监督对比学习,它会利用“标签”信息。
- 目标:拉近所有“同类”样本(比如,所有“苹果黑星病”图片的向量),同时推远所有“不同类”样本(比如,“苹果黑星病”和“玉米叶斑病”的向量)。
这个阶段的最终成果是什么?
很重要的一点是,这个阶段的产物不是一个分类器。如论文第5页所述,它的输出是一个训练得非常好的编码器网络 Enc(·)这个编码器现在非常擅长提取病害特征,能把同类病害的图片在特征空间中“聚拢”在一起。
2.2 数据增强的具体方法
我们来看看论文 3.2 节(第9页)的具体内容。
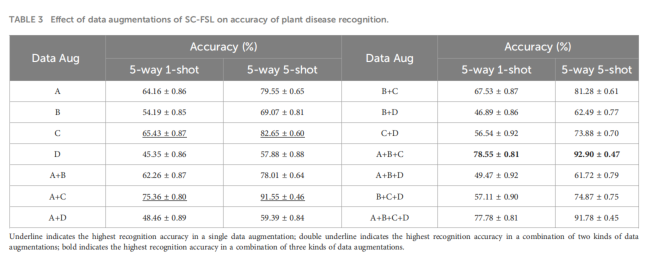
作者测试了四种主要的数据增强方法,并给它们分配了代号以便于组合测试:
For simplicity, we denote A, B, C and D to represent 4 kinds of data augmentations.
Trans:为简化表述,我们用A、B、C和D分别表示四种数据增强方法。
A is the random length width ratio cropping, and the random cropping area ratio is 0.2-1.0.
B denotes the random horizontal flipping of the images according to the probability, and the flipping probability is 0.5.
C is the image color distortion operation that modifies brightness, contrast, and saturation, and for which a probability of 0.8 is applied.
D denotes the random conversion of images to grayscale images.
- A:随机长宽比裁剪(以及 0.2-1.0 的随机裁剪面积)
- B:随机水平翻转(概率为 0.5)
- C:图像颜色失真(修改亮度、对比度和饱和度,概率为 0.8)
- D:随机转换为灰度图像
他们通过实验(如表3所示)来找到效果最好的组合。
- 在三种方法组合中,A+B+C(裁剪 + 翻转 + 颜色失真)的识别准确率最高。
- 他们还发现,任何包含 D(随机灰度) 的组合都会导致准确率下降。
This operation causes the disease image to lose its color. Therefore, it is reasonable to speculate that in the supervised contrastive learning, the color information of thedisease enables the encoding network to pull samples of other categories further apart. If the color information is lost, the encoding network cannot effectively cluster the samples of the same disease.
Trans:该操作会导致疾病图像颜色信息丢失。因此可以合理推测,在监督对比学习中,疾病颜色信息能使编码网络将不同类别的样本进一步区分。若颜色信息丢失,编码网络将无法有效对同种疾病的样本进行聚类。
论文推测,这是因为颜色信息对于编码器区分不同病害非常关键,而灰度操作会丢失这些信息。
2.3 投影仪的去向
Projection Network, denoted as Proj(•), maps the representation vector obtained after the encoding network to the contrastive loss space. Usually, Proj(•) is instantiated as a Multi-Layer Perceptron (MLP) and discarded after the contrastive training (Tian et al., 2020).
Trans:投影网络(Proj(•))将编码网络生成的表征向量映射至对比损失空间。该网络通常采用多层感知器(MLP)实现,并在对比训练完成后被丢弃(Tian等人,2020)。
简单来说:
- 第一阶段(训练):需要“投影仪” (Proj(•))。它的唯一工作是辅助计算“对比损失”。它将编码器 Enc(•) 产生的特征 h 映射到另一个空间,以便模型更有效地“拉近”同类、“推远”异类。
- 第二阶段(测试/应用):不需要“投影仪”。我们真正需要的是那个训练好的编码器 Enc(•) ,因为它学会了如何从原始图像中提取出有意义的、可区分的特征(向量 h)。
因此,训练结束后,我们就扔掉“投影仪”这个脚手架,只保留最有价值的“编码器” Enc(•)。
3.深入了解 第二阶段
最近质心分类 (Nearest-centroid Classification)。
现在我们有了第一阶段训练好的、强大的编码器 Enc(•)(在图1和图3中被称为 fθ)。在第二阶段,我们冻结 (freeze) 这个编码器,不再改动它。
这个阶段就是真正执行“小样本”任务的地方,它会用到两个小数据集:
- 支持集 (Support Set):这是我们仅有的少量训练样本。比如,在一个“5-way 1-shot”任务中,支持集就只有 5 个类别,每个类别 1 张图片。
- 查询集 (Query Set):这是我们需要分类的“新”图片。
具体流程如下(可以参照图 3 ):
- 计算“类别原型” (Class Prototypes) μ:
- 我们把“支持集”中的所有图片(比如那 5 张图)都送入我们冻结好的编码器 fθ,得到它们各自的特征向量。
- 对于同一个类别的所有样本(在这个 1-shot 例子中只有一个),我们计算它们特征向量的平均值。
- 这个平均向量 μ 就成了一个“类别原型”(也叫“质心”),它代表了这个类别在特征空间中的“中心点”。
- 分类“查询集” (Query Set) 图像:
- 我们拿一张“查询集”里的新图片,同样用编码器 fθ 把它转换成一个特征向量。
- 接着,我们计算这个新向量与所有“类别原型” μ 之间的距离(论文中使用了欧氏距离)。
- 这个新图片离哪个“类别原型”最近,它就被归为哪一类。
这就是整个算法的核心:先用“监督对比学习”把同类病害在特征空间中“聚拢”起来(第一阶段),再通过计算新样本离哪个“聚拢中心”(原型)最近来进行分类(第二阶段)。
4.实验设置
他们使用了两个关键的数据集:
The first is PlantVillage (Hughes and Salathe, 2016) which is the most widely used open-access plant disease image database. It collects 54,306 images of plant disease leaves, including 14 kinds of plants and a total of 38 classes.
Trans:第一个是PlantVillage(Hughes和Salathe,2016),这是目前使用最广泛的开放获取植物病害图像数据库,共收录了54,306张植物病害叶片图像,涵盖14种植物,共38个类别。
PDD includes five types of images of potato leaf diseases, namely early blight, late blight, leaf curl, anthracnose and healthy leaves, with 40 images in each class.
Trans:PDD包含马铃薯叶病的五种典型图像类型,分别是早疫病、晚疫病、叶卷病、炭疽病和健康叶片,每类图像各包含40张。
- PlantVillage 数据集:
- 这是一个非常著名和广泛使用的公开数据集。
- 它包含了 14 种植物、共 38 个类别的 54,306 张图片。
- 关键特点:这些照片都是在实验室条件下拍摄的,背景非常干净、单一。
- PDD (马铃薯病害数据集):
- 这是作者自己从互联网上收集的数据集。
- 它只包含 5 个类别(早疫病、晚疫病、卷叶病、炭疽病和健康叶片)。
- 关键特点:这些照片都是在自然场景下拍摄的,光照条件多变,背景非常复杂。
基于这两个数据集,作者设计了两种测试“情景” (Scenarios) 来评估模型的性能:
- 情景 A:训练和测试数据都来自 PlantVillage。 这用来测试模型在数据特征相似(都是实验室背景)的情况下的表现。
- 情景 B:训练数据来自 PlantVillage,但测试数据来自 PDD。 这是一个更难的“跨域” (cross-domain) 测试,用来检验模型从实验室学到的知识能否“迁移”到复杂的自然场景中。
5.实验结果
5.1 同源数据实验结果
这张表比较了作者提出的 SC-FSL 算法和其他九种流行的 FSL(小样本学习)算法在“情景 A”(数据均来自 PlantVillage)上的表现。
我们先弄清楚两个关键指标:
- 5-way 1-shot:模型需要区分 5 个病害类别,但在“支持集”中每类只给它看了 1 张图片。
- 5-way 5-shot:模型需要区分 5 个病害类别,每类给它看了 5 张图片。
| 算法 | 5-way 1-shot (准确率 %) | 5-way 5-shot (准确率 %) |
| ProtoNet | 75.32 ± 0.80 | 89.70 ± 0.51 |
| MatchingNet | 76.80 ± 0.81 | 87.85 ± 0.56 |
| RelationNet | 74.71 ± 0.83 | 88.90 ± 0.40 |
| ... (其他算法) | ... | ... |
| SC-FSL (本文算法) | 78.55 ± 0.81 | 92.90 ± 0.47 |
It can be seen from Table 4 that among all the algorithms, the SC-FSL achieves the highest recognition accuracy in both 5-way 1-shot and 5-way 5-shot.
核心结论是: 作者的 SC-FSL 算法在 1-shot 和 5-shot 任务上均取得了最高的识别准确率。
这表明,在第一阶段使用“监督对比学习”预训练出的编码器,确实为第二阶段的小样本分类任务提供了非常强大的特征提取能力。
5.2 跨域数据实验结果
这是一个更具挑战性的测试,因为模型在第一阶段是在“实验室”数据 (PlantVillage) 上训练的,但在第二阶段必须去识别“自然场景”下拍摄的马铃薯病害 (PDD) 。
表 5:马铃薯病害识别结果(节选)
| M-shot (样本数) | Resnet18 准确率 (%) | Resnet50 准确率 (%) |
| 1-shot | 43.70 ± 0.63 | 49.12 ± 0.73 |
| 5-shot | 60.48 ± 0.54 | 68.29 ± 0.53 |
| 10-shot | 64.87 ± 0.52 | 73.31 ± 0.46 |
| 30-shot | 69.31 ± 0.50 | 79.51 ± 0.39 |
实验结果显示了两个重要趋势:
- 样本数量仍然关键:即使是小样本,样本量的增加也能带来巨大的提升 。对于 ResNet50,仅有 1 张图片 (1-shot) 时准确率不到 50%,但当样本增加到 30 张 (30-shot) 时,准确率跃升至 79.51% 。
- 更深的网络泛化能力更强:在所有样本数级别上,更深的 ResNet50 网络表现都显著优于较浅的 ResNet18 。这表明在第一阶段(监督对比学习)使用更深的网络,能学到更具泛化能力的特征,这对于跨域任务(从实验室到自然场景)尤为重要。
此外,论文还通过图 10(混淆矩阵) 分析了 30-shot 任务中具体类别的识别情况 :
- 模型对“早疫病” (early blight) 的识别效果最好(准确率 91.5%),其次是“健康”叶片 (82%) 。
- 模型最容易混淆的是“炭疽病” (anthracnose),准确率最低 (70.5%) 。它经常被误判为“健康”叶片或“早疫病” ,作者推测这是因为它们在某些图像上的病斑特征非常相似 。
6.实验结论
However, in agricultural production, the time and place of disease occurrence are random, which makes it difficult to collect large-scale disease samples.
论文明确指出,病害发生的时间和地点是随机的,这使得收集大规模病害样本变得非常困难。
这正是传统深度学习方法(需要大量数据)在这里碰壁的原因。
那么,面对这个“样本很少”的难题,作者在结论中提出的新“范式” (paradigm) 是什么呢?他们是如何分两个阶段来解决这个问题的?
In view of the good generalization performance of contrastive learning, we propose a new few-shot disease recognition paradigm called SC-FSL, that is, big data and contrastive learning in the pretraining stage is used in pre-training phase, and few-shot learning is used in the specific disease recognition stage.
Trans:鉴于对比学习具有良好的泛化性能,我们提出了一种名为SC- FSL 的新型少样本疾病识别范式:在预训练阶段采用大数据与对比学习相结合的方法,而在具体疾病识别阶段则采用少样本学习。
这篇论文的核心贡献就是这个新范式:
- 第一阶段:利用“监督对比学习”和大量相关数据(但不一定是目标病害数据),训练出一个具有强大泛化能力的编码器。它学会了什么是“病害”的通用特征。
- 第二阶段:这个编码器能高效地将同类病害“聚拢”在特征空间中,因此在面对新病害时,只需要几个样本(小样本)就能快速定位这个新类别的“中心点”,从而实现准确识别。
我们已经一起完整地学习了这篇论文,从它的核心术语、两个阶段的算法细节,到实验设置和结果分析。
微信扫描下方的二维码阅读本文
